'Programming' 카테고리의 다른 글
| C++Builder 6 Personal : sn & 설명 (0) | 2013.12.13 |
|---|---|
| 삼성노트북 Fn key code (0) | 2013.11.29 |
| [펌] ASCII & Vitual Key Code- keybd_event() bScanCode설명포함 (4) | 2013.11.29 |
| C++Builder 6 Personal : sn & 설명 (0) | 2013.12.13 |
|---|---|
| 삼성노트북 Fn key code (0) | 2013.11.29 |
| [펌] ASCII & Vitual Key Code- keybd_event() bScanCode설명포함 (4) | 2013.11.29 |
노트북 모델: Sens RF710
BIOS Key code값이 변경됨.
- 위 그림 : Touchpad OFF
- 아래 그림 : Touchpad ON
| google.com에서 open source project 참여 검색결과 (2) | 2013.12.03 |
|---|---|
| [펌] ASCII & Vitual Key Code- keybd_event() bScanCode설명포함 (4) | 2013.11.29 |
| 코드 리뷰 (0) | 2013.08.12 |
My) 아래부분의 1. 배경 지식: 스캔코드의 make와 break 이 제일 중요.
출처: http://900ift.tistory.com/45
ASCII Code Table
접어두기..

접어두기..
Virtual Key Code - http://msdn.microsoft.com/en-us/library/ms645540
접어두기..
| 가상키 코드 | 값 | 키 |
| VK_LBUTTON | 01 | |
| VK_RBUTTON | 02 | |
| VK_CANCEL | 03 | Ctrl-Break |
| VK_MBUTTON | 04 | |
| VK_BACK | 08 | Backspace |
| VK_TAB | 09 | Tab |
| VK_CLEAR | 0C | NumLock이 꺼져 있을 때의 5 |
| VK_RETURN | 0D | Enter |
| VK_SHIFT | 10 | Shift |
| VK_CONTROL | 11 | Ctrl |
| VK_MENU | 12 | Alt |
| VK_PAUSE | 13 | Pause |
| VK_CAPITAL | 14 | Caps Lock |
| VK_ESCAPE | 1B | Esc |
| VK_SPACE | 20 | 스페이스 |
| VK_PRIOR | 21 | PgUp |
| VK_NEXT | 22 | PgDn |
| VK_END | 23 | End |
| VK_HOME | 24 | Home |
| VK_LEFT | 25 | 왼측 커서 이동키 |
| VK_UP | 26 | 위쪽 커서 이동키 |
| VK_RIGHT | 27 | 오른쪽 커서 이동키 |
| VK_DOWN | 28 | 아래쪽 커서 이동키 |
| VK_SELECT | 29 | |
| VK_PRINT | 2A | |
| VK_EXECUTE | 2B | |
| VK_SNAPSHOT | 2C | Print Screen |
| VK_INSERT | 2D | Insert |
| VK_DELETE | 2E | Delete |
| VK_HELP | 2F | |
| 30~39 | 숫자키 0~9 | |
| 41~5A | 영문자 A~Z | |
| VK_LWIN | 5B | 왼쪽 윈도우 키 |
| VK_RWIN | 5C | 오른쪽 윈도우 키 |
| VK_APP | 5D | Application 키 |
| VK_NUMPAD0~VK_NUMPAD9 | 60~69 | 숫자 패드의 0~9 |
| VK_MULTIPLY | 6A | 숫자 패드의 * |
| VK_ADD | 6B | 숫자 패드의 + |
| VK_SEPARATOR | 6C | |
| VK_SUBTRACT | 6D | 숫자 패드의 - |
| VK_DECIMAL | 6E | 숫자 패드의 . |
| VK_DIVIDE | 6F | 숫자 패드의 / |
| VK_F1~VKF24 | 70~87 | 평션키 F1~F24 |
| VK_NUMLOCK | 90 | Num Lock |
| VK_SCROLL | 91 | Scroll Lock |
접어두기..
Scan Code - http://www.microsoft.com/whdc/archive/scancode.mspx
접어두기..


접어두기..
한영키와 한자키 스캔코드의 비밀 - http://www.kbdmania.net/xe/tipandtech/1737860
접어두기..
접어두기..
| 삼성노트북 Fn key code (0) | 2013.11.29 |
|---|---|
| 코드 리뷰 (0) | 2013.08.12 |
| [펌] Winsock(소켓)설명_좋음 (0) | 2013.08.09 |
'소프트웨어 개발의 모든 것' 중에서 - 김익환,전규현
------------------------------------------------------------------------
코드 리뷰
테스트를 통해서 소프트웨어의 모든 결함을 찾아낼 수는 없으며, 아키텍처, 코
드 리뷰를 통해서 오류의 상당 부분을 찾아낼 수 있다. 코드 리뷰를 충분히 하지
않으면 수많은 결함들이 테스트에서도 발견되지 않은 상태로 제품이 출시될 것
이다
출시 후에 발견된 결함은 그를 수정하기 위해서 코드 리뷰 때 수정하는 것에
비하여 수백 배의 비용을 치르게 만든다. 철저한 코드 리뷰는 소프트웨어의 품질
을 한 단계 높이고 개발 비용을 절야할 수 있는 좋은 수단이다. 코드 리뷰를 통해
서 오류를 찾아내는 효울은 테스트보다 2배 더 높다는 것이 알려진 사실이다.
코드 리뷰는 조금씩 자주 수행하는 것이 좋다. 소스코드를 소스코드관리시스
템에 체크인하기 전에 리뷰하면 효과적이다. 검토되지 않은 코드는 소스코드관
리시스템에 등록하지 않도록 규칙을 정하는 것이 좋다. 체크인 전의 리뷰는 1, 2
명의 간단한 검토로 리뷰를 마치게 할 수도 있다. 이는 일반적인 대규모 코드리
뷰 희의보다 더 효율적이다.
내가 작성한 소스코드는 항상 검토의 대상이라고 생각하고 코드를 작성하게
된다. 그렇게 하면 항상 회사의 코딩 표준을 지키기 위해서 노력을 하고, 창피한
코드는 작성하지 않으려고 할 것이다. 코드 리뷰 시는 다음과 같은 사항들을 주
의하여야 한다.
ㅁ 너무 많은 개발자가 참여하면 안 된다. 너무 많은 개발자는 코드 리뷰를 어
수선하게 하여 집중할 수 없게 만든다
ㅁ 검토 시에 상대방을 비난하는 투로 말하면 안 된다. 이런 방식은 싸움판만
만들 것이고 개발자들은 더욱 코드 리뷰를 꺼리게 될 것이다
ㅁ 스티.일에 대해서 자기 주장을 강요하지 않는 것이 좋다. 회사의 코딩 표준을
다 따르더라도 각 개발자의 스타일에 따라서 코드를 다르게 작성하는 것이
꽤 될 것이다. 이러한 스타일을 가지고 자신의 스타일과 다르다고 비난하는
것은 시간 낭비일 뿐이다
ㅁ 코드리뷰는 진행자가 전체적인 진행을 조정해야 한다. 그러지 않으면 1시
간 예상한 코드 리뷰가 2, 3시간이 되기 일쑤이고, 전체 코드를 점검하지도
못하게 된다. 또는 코드 리뷰가 이상한 방향으로 흘러서 코드를 공유하고 개
선하는 데는 별로 도움이 안되기도 한다
ㅁ 가능하면 코드 리뷰 전에 코드를 읽어보고 들어오는 것이 좋다. 짧은 시간에
남의 코드를 모두 이해하는 것은 쉽지 않다
ㅁ Syntax를 코드 리뷰 시간에 의논하는 것은 시간낭비다. Syntax는 점검은 정
적분석기를 이용하면 된다. 코드 리뷰시간에는 코드의 의미, 구조와 같이 가
치 있는 리뷰를 해라.
코드 리뷰는 대단히 기술적인 작업이다. 뛰어나고 숙련된 개발자가 코드 리뷰
경험이 많을 경우에만 능숙하게 할 수 있다. 별 준비 없이 그냥 나란히 같이 앉아
서 소스코드를 보는 것이라면 안 하는 것보다야 훨씬 낫겠지만, 효율은 상당히
띨어질 것이다. 따라서 코드 리뷰 시에 무엇을 위주로 점검해야 하는지 체크리스
트를 만들어서 암기하고 있으면 상당히 도움이 된다.
----------------------------------------------------------------------------
| [펌] ASCII & Vitual Key Code- keybd_event() bScanCode설명포함 (4) | 2013.11.29 |
|---|---|
| [펌] Winsock(소켓)설명_좋음 (0) | 2013.08.09 |
| UML - Class Diagram 관계 샘플(좋음) (0) | 2013.07.26 |
원저자: 정현호.
--------------------------------------------------------------------------------
WinSock을 이용한 네트웍 프로그래밍
--------------------------------------------------------------------------------
WinSock을 이용한 네트웍 프로그래밍 #00 지은이 : 정현호
다시 강좌란에 글을 올리게 되어 기쁩니다. 그동안 더 많이 발전을 했어야 여러분
들께 좋은 글을 드릴텐데, 잘 모르겠습니다. ^^; 그동안 짧게나마 네트웍 프로그래
밍을 하며 얻은 것들을 여러분과 나누려 합니다. 지난번에 올린 글과 마찬가지로
그렇게 고급스러운 내용을 다루는것도 아니고 남과 다른 방법을 제시하는것도 아닙
니다. 지금까지 그래왔고 앞으로도 그럴것이지만, 처음 시작하시는 분들께 가이드
라인을 잡아드리는 정도의 수준일 것입니다.
[윈도우 소켓을 이용한 네트웍 프로그래밍]
0. 현재 보고 계신 머릿말 비슷한 잡담. ^^;
1. 소켓 프로그래밍을 위한 통신 개론.
2. 윈도우 소켓이란?
3. 윈도우 소켓 초기화와 서버 프로그램
4 클라이언트 프로그램.
5. 쓰레드( Thread ).
6. 윈도우 소켓을 이용한 데이터 송수신.
7. TCP와 UDP의 차이점.
8. 프로토콜 설계와 보안문제.
9. 채팅 서버/클라이언트 프로그램을 만들어 봐요~
대강 이정도네요. 아직 깊게 공부를 하지 못해서 실제 상용 네트웍 게임에서나 볼
수 있는 노하우들까지는 못 다루지 못 할것 같습니다만, 그 노하우 부분은 여러분
들 자신 직접 얻어야할 부분이라 생각합니다. 모르는 걸 이런 핑계로 넘기는 ^^;
아마도 저나 네트웍을 처음 공부 하시는 여러분이나 가졌던 의문이나 어렵게 느끼
고 있었던 혹은 어렵게 느낄 부분은 그렇게 다르지 않을 것이라 생각합니다. ^^;
그래서 앞으로 진행될 내용들 대부분이 제가 어렵게 혹은 의아하게 생각했던 부분
들이 되지 않을까 싶습니다. 네트웍에 대한 기초 지식이 부족한 저이지만 제 글이
새롭게 이 네트웍이라는 분야에 입문하신 분들께 작게나마 도움이 되었으면 합니
다.
[준비물]
0. 쌩쌩한 컴퓨터 한 대.
1. 윈도우 계열의 운영체제.(가능하면 98/윈2K)
2. 윈도우 소켓 API를 처리할수 있는 컴파일러( VC++ )
3. Lan카드(테스트용으로 필수입니다. 없으면 당장 구비하십시요.)
4. 윈도우 소켓 관련문서 혹은 책. 있으면 좋고 없으면 없는데요...... ^^;
5. 기초적인 C언어 구현능력.
6. 근성( 가장 중요하죠. ^^ )
당연한 이야기지만 모뎀, 랜카드, 혹은 IP업체(두루넷, 드림라인등)에서 IP를 할
당 받으셔야합니다. 그래야 통신을 하기위한 하드웨어가 마련되는 셈이죠. 가장 가
격대 성능비가 좋은건 랜카드만 달랑 장비하는 경우입니다. 용산가면 대만제 1만원
선 제품들이 많습니다. 현재 100메가 제품이 많이 유통되고 있을겁니다. 모뎀은 현
실적으로 무리가 많죠. 전화 요금문제도 있고 느린 속도등 문제가 많죠. 다음은
IP업체에 가입하는 경우인데, 아직까지도 두루넷이 깔리지 않는 지역도 있고 달마
다 내는 요금이 부담이 되는경우도 있을겁니다. 가장 싼 맛에 할 수 있는 방법은
랜카드만을 장착하고 가상으로 데이터를 송/수신해 보는 겁니다. 저도 처음에 이
방법으로 시작했고, 무리도 없었습니다. 물론 가상으로 자신의 컴퓨터안에서 데이
터를 주고 받기 때문에 실제 네트웍에서 발생할수 있는 문제에 대한 대처라든지
실제 네트웍 속도를 느낄수 없다는 단점이 있기는 하지만, 처음에 잘 모르는데
괜히 비싼돈 들여가면서까지 할 필요는 없다고 봅니다. ^^;
그나저나 이번 글은 상당히 부담이 되는군요. 뭐 언제나 그렇듯이 제가 아주 잘
해서 글을 올렸던 경우는 없었지만요. ^^; 이번은 정말 거의 무모할 정도로 그냥
쓴 것이 아닐지라는 의문이 있네요. 결과는 제 글과 예제를 마지막까지 보신후면
나올테지만 오히려 처음 접하는 분들께 더 혼란을 주는건 아닌지 걱정입니다.
"처음 시작하시는 분들께 좋은 가이드 라인이 되었으면......" 이라는 희망을
가지고 계속 이어나가겠습니다.
WinSock을 이용한 네트웍 프로그래밍 #01 지은이 : 정현호
* 이번 게시물은 가벼운 마음으로 읽어주시면 됩니다. 하지만, 게시물 후반부에 나
오는 OSI 7 Layer는 꼭 이해를 해 주셔야 합니다. 네트웍에 대한 기초적인 구조
를 이해할 수 있는 부분이기 때문입니다. 또한 IP, 포트, 패킷에 관한 개념 이해
또한 필수입니다.
[윈도우 소켓을 이용한 네트웍 프로그래밍]
*[송수신 방식에 따른 분류]
*[네트웍 토플로지]
*[On Line / Off Line]
*[OSI 7 Layer]
*[인터넷에서 데이터는 어떻게 전송될까?]
1. 소켓 프로그래밍을 위한 통신 개론.
통신이 뭘까요? 국어 사전에서 정확한 정의를 찾아 보지는 않았습니다만, 자신의
의견을 남에게 알리는 방법들을 통신이라고 할 수 있다고 생각합니다. 지금 여러분
은 제 글을 읽고 계시고 저는 여러분과 저는 통신을 하고 있습니다. 이렇게 따지면
통신의 방법은 아주 많죠? 전화, TV, 컴퓨터 통신, 인터넷등등 생각해 보면 꽤 많
은 방법으로 인간은 소식을 전할 수 있고 전달 받을수 있습니다. 앞으로 여러분들
과 같이 다루게 될 내용은 그 중 한 가지인 컴퓨터를 이용한 통신입니다. 많은 통
신 방법 중 단지 하나를 다루는 것 뿐입니다. 항상 이점을 명심하세요. 통신은 자
신의 의견을 남에게 알리는 한가지 방법일 뿐이라는 점. 그리고 그렇게 하려면 어
떻게 해야 할까?에 대한 물음과 그에 대한 답을 찾아 보십시요. 그것이 통신 프로
그램을 짜야할 여러분들이 앞으로 나가야할 방향입니다. 단지, 여러분들은 다른 사
람들과 달리 컴퓨터를 이용하는 것뿐입니다.
아래에 나오는 내용들은 앞으로 여러분들과 같이 윈도우 소켓프로그램이라는 것을
알아나가는데 그리 큰 역할을 하지는 않지만, 상식 차원에서 다룬 부분들입니다.
꼭 외울 필요가 없는 부분도 있고 꼭 알야할 부분도 있습니다. 게시물 전반부에서
중요하다고 언급한 부분들만 중점적으로 봐 두시면 도움이 될 것입니다.
-[송수신 방식에 따른 분류]---------------------------------------------
*심플렉스(Simplex)
A -> B
한 지점에서 다른 지점으로만 보낼 수 있는 방식입니다. 가장 좋은 예는 TV나 라디
오 같은 통신 매체 같습니다. 물론 시청자 소감이나 방송국에 항의를 하면 양 방향
통신이라고 생각 할수도 있겠습니다만...... ^^; 대부분 TV를 통해 한 곳에서 보내
는 방송을 일방적으로 보고 듣기에 위와 같이 설명을 했습니다.
*하프-듀플렉스( Half-Duplex )
A -> B 또는 A <- B
양방향 통신이 가능하긴 하지만, 한 쪽에서 다른 쪽으로 통신 내용을 보내고 있을
때 반대쪽은 받을수만 있고 보내지는 못하는 경우라고 생각하시면 간단하리라 봅니
다. 마땅히 좋은 예가 떠오르지는 않지만, 우편 시스템을 생각해 보면 어떨까요?
한쪽에서 편지를 쓰면 반대쪽은 편지를 받고 다시 반대쪽으로 답신을 하는 상황.
양쪽으로 통신이 이루어지는 하지만, 동시에 이루어지지는 않는 경우죠.
*풀-듀플렉스( Full-Duplex )
A <-> B
양 방향 통신이 가능한 경우입니다. 전화가 좋은 예겠군요.
생각해 보면 위의 용어들만이 낮설을 뿐이지 여러분들은 모두 한번씩은 경험해 보
신 친근한 방식들이라 생각됩니다. 알게 모르게 여러분이나 저나 통신에 대해 많은
것들을 알고 있다는 사실은 아래의 글들에서 또 확인하게 될 것입니다. 사실 누구
나 생각할 수 있는 것 들일지도 모르겠습니다. 단지, 누군가 먼저 이론화 했을 뿐.
=[송수신 방식에 따른 분류]
===================================================
-[네트웍 토플로지]----------------------------------------------------------
기억이 확실치는 않지만, 토플로지는 지형학을 뜻한다고 들었던것 같습니다. 어찌
되었든, 잘 생각해 보면 네트웍의 구성도를 보면, 몇몇 특징적인 연결도(지형도)를
그려낼 수 있습니다. 각각의 방식엔 장점 및 단점이 있습니다만 외우실 필요는 없
습니다. ^^;
*링
말 그대로 반지와 같은 구조입니다. 여러대의 컴퓨터가 서로 이웃된 컴퓨터와 선로
를 통해 연결되어 있는 구조입니다. 장점은 어느 선로 하나가 끊겼을 경우에 통신
에는 문제가 없다는 점이죠. 단점은 데이터 하나를 보내기 위해 여러 컴퓨터를 거
친다는 점 이겠군요.
*스타
어떤 중앙 서버 한대가 있고, 단말기 형태의 컴퓨터들이 서버에 연결되어 있는 경
우죠. 불가사리를 연상하시면 좋을듯 하군요. 이 토플로지의 단점은 중앙 제어 장
치에 문제가 생기면 모든 터미널 사이의 연결이 끊어져 버린다는 점 입니다. 하지
만, 터미널이 몇 대가 고장나든 상관은 없겠죠? ^^;
*버스
고속도로 휴게소A에서 휴게소 B로 물건을 배달하는 시스템을 생각해 보시는게 좋겠
군요. 고속도로에 끊기는 곳만 없다면 어느 휴게소든 물건을 배달할 수 있겠죠? 마
찬가지로 여러대의 컴퓨터는 하나의 선로를 공유하고 그 선로를 통해서 자신의 원
하는 컴퓨터로 메시지를 보낼수 있는 방식입니다. 이 방식의 약점은 모두가 공유하
고 있는 선로가 파손 되었을때 모든 시스템이 고립된다는 점이죠. 스타 방식에서
중앙 제어장치가 고장나듯이요.
위의 구조중 어떤 방식이 최선이라고 정의를 할 수는 없습니다. 역시 가장 중요한
점은 가격대 성능비겠죠. 투자될 선로비가 컴퓨터보다 싼지 아닌지에 따라 선로의
안정성이 중요한지 제어장치(컴퓨터)의 안정성이 중요한지에 따라 선택을 해야할
문제니까요.
=[네트웍 토플로지]
===========================================================
-[On Line / Off Line]--------------------------------------------------
------
*On Line
말 그대로 선이 연결되어 있는 경우입니다. 여러가지 예가 있겠죠? 은행에서 다른
곳으로 돈을 보낸다든지 하이텔에 접속해서 데이터를 다운로드를 받는경우. 혹은
대화 방에서 채팅을 하는경우 전화 등등...... ^^;
위 예들의 공통점이자 Off Line과의 차이점은 어떤 선로를 통해 데이터를 주고 받
는 다는 점입니다. 장점은 역시 즉각적인 답을 얻을수 있다는 점입니다만, 선로를
통해 보낼수 없는 것들이 더 많다는 점이겠죠. ^^;
*Off Line
끊어진 선. (-_-;) 어떤 선로를 통한 통신이 아닌 경우를 생각하시면 되겠죠? 자
주 하실지는 모르겠지만, 오프라인 모임이라든지 소포를 보내는 경우겠죠. 단점은
온라인과 반대로 즉각적인 답을 얻을수 없다는 점이지만, 선로를 통해 보낼 수 없
는 데이터를 주고 받을 수 있다는 점이겠죠. 온라인 대화에서 느낄수 없는 사람의
느낌이랄까요? ^^;
=[On Line / Off Line]
========================================================
-[ OSI 7 Layer ]------------------------------------------------------
네트웍 상에 연결되는 시스템의 이상적인 표준 모델을 정의한 계층입니다. 개념 이
해가 중요합니다. 깊게 공부할 필요는 없지만, 7가지 계층의 관계와 실제 그 계층
들이 실제 여러분들이 사용하시는 인터넷에서 어떤 역할을 하는지는 꼭 파악을 해
두셔야만 합니다. 제가 설명을 하려고 했지만, 어설픈 제 설명보다는 서점에 널려
있는 네트웍 책 중 아무거나 한 권 잡고 보시면 될 부분이기에 설명은 생략합니다.
참고로 다 보시기 귀찮으시면 아래 4가지 계층을 중점적으로 보십시요.
1. 물리
2. 네트워크/링크
3. 전송
4. 애플리케이션.
위의 4가지 계층을 꼭 숙지하시고 다음 게시물을 읽어 주시기 바랍니다.
=[ OSI 7 Layer ]
=============================================================
-[인터넷에서 데이터는 어떻게 전송될까?]---------------------------------
우선 몇가지 용어에 대한 정의를 해야할것 같습니다.
*IP : 네트웍 상에서의 주소.
*Port : IP로 들어오는 패킷을 구분지어주는 구분자(?)
*Packet : 보낼 데이터를 적당히 잘라놓은 조각.
좀더 다세히보도록 하죠.
I P : 네트웍상에서의 주소라고 생각하시면 간단합니다. 당연한 이야기지만, 전화
를 하려면 전화번호가 필요하고 우편물을 보내려면 주소가 필요합니다. 이와
마찬가지로 컴퓨터사이의 통신에서는 IP라는 주소가 사용됩니다.
그 형식은 아래와 같습니다.
ex) 169.254.34.243 ( 0~255.0~255.0~255.0~255 )
포트 : 주소만 안다고 물건을 원하는 사람에게 정확하게 전달할수 있을까요? 그
물건을 받을 사람의 이름이 있어야 정확히 전달이 될것입니다. 주소가 맞
아도 이사를 갔다거나 받는 사람의 이름을 알지 못하면 우편 배달부는 난감
할 것입니다. 같은 IP로 데이터들이 와도 포트에 따라 그 데이터들이 분류
됩니다. 컴퓨터로 생각하면 컴퓨터에 데이터가 수신되었을때, 그 데이터
가 사용될 프로그램을 구분 지을 구분자정도로 생각하시면 간단할 겁니다.
ex) 5001 ( 0~65535 )
패킷 : 패킷은 우편물 정도로 생각하시면 간단합니다. 즉, 실제로 보낼 데이터라고
생각하시면 됩니다. 그 내용은 보내는 사람의 마음이겠죠? ^^;
우선 컴퓨터에 대한 설명을 하기전에 우리 일상을 생각해 볼까요? A지점에서 B지
점으로 많은 사람이 이동한다고 가정을 해보죠. 이동 방법은 자동차, 기차, 비행기
, 배 이렇게 4가지가 있다고 생각을 해 보죠. 같은 시간에 가장 많은 사람을 A지점
에서 B지점으로 이동시킬수 있는 방법은 4가지 교통수단을 이용할 사람의 수를 적
당히 분배하고 적당한 이동 경로를 지정하는 방법일 겁니다. 인터넷에서 데이터를
보내는 방법도 위와 크게 다르지 않습니다. A지점에서 B지점으로 데이터를 보낼 때
효율적인 전송을 위해 그 데이터를 적당한 단위로 끊고 적당한 경로를 지정해 주면
됩니다. 그럼 위의 경우를 용어로 정리를 해보겠습니다.
앞에서 이야기 한 부분과 크게 다른 부분은 없지만, 용어 파악을 위해 다시 한번
쓰겠습니다. 어려분 컴퓨터(이하 A)의 어떤 데이터를 다른 컴퓨터(이하 B)로 보낸
다고 가정을 해 보죠. A에서 데이터를 B로 보내기위해 우선은 데이터를 알맞은 크
기로 즉, 패킷 단위로 자릅니다. 그리고 그 패킷에는 이 찾아가야 할 컴퓨터의 네
트웍상의 주소(IP)가 있어야겠죠? 그런데, IP가 지정되었다고 B를 찾아갈때 아무렇
게나 가지는 않겠죠? 당연히 가장 빠르게 갈 수 있는 길을 찾아내서 그 길로 가야
할 것입니다. 어찌되었든, 보내온 데이터 즉, 패킷이 다 모아지면, OK신호를 보내
고 그 데이터는 B에서 인정이 되는거죠. 그런데, 만약 통신 프로그램에 IP만 있다
면 컴퓨터 하나당 통신 프로그램은 단 하나밖에 존재할 수 없을 것입니다. 그걸 보
완하기 위한 개념을 포트라고 생각을 하시면 됩니다. ^^; 즉, IP로 상대방의 컴퓨
터 주소를 적어주고 포트로 받을 프로그램을 지정해주는 거죠.
=[인터넷에서 데이터는 어떻게 전송될까?]
======================================
-[자신의 IP확인하기]--------------------------------------------------------
당연한 이야기지만 네트웍 프로그램을 하려면 기본적으로 통신 장치가 있어야합니
다. 모뎀, 랜카드, 두루넷이나 드림라인같은 서비스에 가입등의 방법으로 자신의
IP를 할당 받아야합니다. 모뎀의 경우는 전화접속 네트워킹으로 통신사에 접속을
하고 IP를 배당받는 방법이 있겠고, 랜카드는 장착만 해도 가상의 IP를 얻을수 있
습니다. 또하나의 방법은 두루넷이나 드림라인같은 전용선 업체에 가입해서 IP를
할당받는 방법입니다. 그냥 랜카드만 있으면 가상으로 밖에 체크가 않되지만 IP를
할당 받으면, 실제로 데이터를 주고받아 볼수 있습니다만 랜카드만으로 가상의 테
스트를 해 보는 방법도 나쁘지는 않습니다. 저도 처음엔 그렇게 했었습니다. 그래
서 앞 게시물에서 랜카드를 싸구려라도 하나 정도는 꼭 구비해 두라고 했었죠.
노파심에서 하는 이야기지만, 운영체제에 따른 아래의 테스트를 꼭 해주십시요.
그리고 자신의 IP를 확인하는 법을 꼭 찾으십시요.
윈도우 98과 윈도우 2K의 경우 조금 다릅니다.
윈도우98 : 시작버튼을 누른다.
실행을 선택.
winipcfg를 입력후 엔터하시면 프로그램이 하나 뜹니다.
모뎀이 있으신분은 PPP Adapter가 있을겁니다. 전화전속 네트워킹으로
연결을 하신상태면 할당받은 IP가 나올테고, 아니면 알수 없는 숫자들
이 나와있습니다. 만약 랜카드만 있으시면, PPP Adapter가 없고 대신
랜카드와 관련된 정보가 보일겁니다. 모뎀과 랜카드가 같이 있으시면
PPP Adapter콤보 박스를 드랍다운 시켜보십시요. 나옵니다. 그리고 선
택하면, IP정보를 확인할수 있습니다.
또 하나의 방법. 그냥 도스창에서 ipconfig입력을 넣습니다.
윈도우2K : 시작 버튼을 누른다.
보조프로그램
명령 프롬프트
도스창에서 ipconfig라고 칩니다.
IP, Subnet Mask, Gateway가 나옵니다만 우리가 필요한 것은 IP뿐
랜카드만 달랑 달아 놓으셨다면, 자동으로 잡힌 IP가 보일겁니다.
만약 IP를 할당 받으셨다면 할당된 IP가 나오겠죠? ^^;
Tip : 아마도 랜카드만으로 가상의 네트웍 환경을 만들어 쓰실 분들이 많을겁니다.
현실적으로 모뎀으로 하기엔 무리고 그렇다고 IP 서비스 가 전역으로 퍼진
상태가 아니니까요. 그럴경우면 윈도우 2K에서 랜카드를 설치하고 하십시요.
윈도우 98은 시동될때마다 가상의 IP주소를 계속 바꿉니다. 나중에 이문제는
꽤 귀찮아집니다. 하지만 윈도우 2K는 전혀 변함이 없져. 한 번 설정된 값을
계속 유지합니다. 하지만 윈도우 98에서도 해결법은 있습니다. ^^;
네트워크 환경에서 오른쪽 버튼을 누르고 등록정보를 선택합니다. TCP/IP
등록 정보를 선택하고 그 안에서 IP정보를 선택합니다. 여기에 IP를 자동으
로 할당함이라는 라디오버튼을 해제하고 IP를 강제로 지정해 버리는겁니다.
그러면 그 IP로 계속 유지됩니다.
=[자신의 IP확인하기]
=========================================================
쓰고보니 정말 날림 기본 정리군요. --; 제가 네트웍 프로그램에 처음 접했을때
가장 어려웠던 점이 용어 문제였습니다. 알고 보면 별것도 아니었는데, 처음에 하
나 하나 이해를 해 나가는데, 용어하나를 모르면 이빨이 하나 빠져버린 느낌이었습
니다. 위의 내용들을 뼈대(부실한 ^^)로 서점에서 좀 더 자세한 정보를 얻어 놓으
신후에 다음 절로 넘어 가심이 좋을 듯합니다. 윈도우 소켓 프로그램만을 하는데는
OSI 7 Layer같은게 실제로 중요하지는 않지만 알고 있을경우와 그렇지 않을 경우
상당한 차이가 있습니다. 개인적으로 그 경험을 해봤기에 여러분들께 감히 하시라
고 지속적으로 이야기를 하고 있습니다. ^^;
[주의] 다시 하번 강조하지만 OSI 7 Layer, IP, 포트, 패킷은 꼭 이해를 해 주셔
야합니다. 그리고 IP확인도 꼭 해보세요.
WinSock을 이용한 네트웍 프로그래밍 #02 지은이 : 정현호
* 이번 게시물에선 앞으로 여러분들과 다루게 될 윈도우 소켓에 대해 설명을 하겠
습니다. 앞으로 가장 자주 쓰이게 될 개념이므로 확실하게 이해를 해 두서야 합
니다.
[윈도우 소켓을 이용한 네트웍 프로그래밍]
[윈도우 소켓이 뭐길래?]
[파일 포인터를 먼저 봐요.]
[윈도우 소켓과 파일 포인터의 관계는?]
2.윈도우 소켓이란?
[윈도우 소켓이 뭐길래?]
앞으로 여러분과 제가 가장 자주 다루게 될 물건(?)인 소켓은 아래와 같이 선언합
니다.
SOCKET MySocket;
간단하죠? 그럼 SOCKET이 어디에 어떻게 선언이 되어있는지 확인해 보도록하죠.
컴파일러(VC++ 기준)의 인클루드 폴더의 WinSock.h를 보시면 35번째 줄에 아래와
같이 선언이 되어 있습니다.
typedef u_int SOCKET;
한마디로 "unsigned int"였던 것이었습니다. ^^; 윈도우 계열 네트웍 플밍의 핵심
인 윈도우 소켓이라는게 unsigned int라니 조금은 실망한 분들이 많을듯 하군여.
저도 처음엔 무슨 대단한 구조체인줄 알았는데, 막상 찾아보니 저 모양이더군요.
[파일 포인터를 먼저 봐요.]
윈도우 소켓을 보기전에 파일 포인터를 생각해 보도록하죠. 파일을 제어하기 위해
파일 포인터 사용하셨던 기억을 되살려 보도록 하죠.
FILE *file;
file = fopen( "MyText.Txt", "rb" );
fread( &Val, size, count, file );
.
.
.
fwrite( &Val, size, count, file );
fclose( file );
보통 위와 같이 했었죠? 저만 위와같이 했나요? 어찌되었든, fopen이라는 함수를
통해 file이라는 포인터는 MyText.txt라는 파일을 대표하는 ID가 되었습니다. 그
뒤에 파일에서 데이터를 읽어낸다든지, 파일로 데이터를 기록한다든지 할 때, 항상
file이라는 ID를 이용하죠. 파일을 다 사용했으면, fclose라는 함수로 file이라는
ID는 더이상 쓰지 않겠다고 알려줍니다. 왜 갑자기 파일 포인터를 이야기 했냐면?
앞으로 여러분께서 사용하실 윈도우 소켓이 위의 예에서 다룬 file 포인터와 아주
비슷하게 사용되기 때문입니다. 다음 게시물에서 구체적으로 어떻게 다룰지를 이야
기 하겠습니다. 현재 게시물에서는 위에 제가 이야기한 정도만 아시면 충분하리라
생각합니다.
[윈도우 소켓과 파일 포인터의 관계는?]
아래에 실제로 소켓이 어떻게 쓰이는지 예를 보이겠습니다. 위의 파일 포인터 사용
과 어떤점이 비슷한지 유심히 살펴 보십시요. 처음보는 함수들의 기능에 대해서는
몰라도 됩니다. 바로 다음 게시물에서 자세히 이야기하겠습니다. 지금은 문장 형식
에만 관심을 가지고 보십시요. SOCKET이 어떻게 쓰이는지...... ^^;
//소켓의 역할은?------------------------------------------------------------
SOCKET ServerSocket; //서버소켓
SOCKADDR_IN ServerAddress; //주소에 관련된 구조체
ServerAddress.sin_family = AF_INET;
ServerAddress.sin_addr.s_addr = INADDR_ANY;
ServerAddress.sin_port = htons( ServerPort=5001 );
//소켓을 생성합니다. 파일 포인터의 FILE *file과 비슷합니다.
ServerSocket = socket(AF_INET, SOCK_STREAM,0);
//파일 포인터로 어떤 파일을 지정하는 부분과 비슷합니다. fopen()과 비슷한
//기능을 합니다.
bind(ServerSocket,(struct sockaddr*)&ServerAddress,sizeof
(ServerAddress));
listen(ServerSocket,SOMAXCONN);
//fwrite나 fread와 비슷하게 실제로 원하는 작업을 가능하게 해 주는 함수들.
send( ServerSocket, SendMessage, SendSize, 0 );
.
.
.
//소켓을 다 쓰면 닫습니다. fclose()와 비슷합니다.
closesocket( ServerSocket );
//소켓의 역할은?
=============================================================
나름대로 파일 포인터와 비슷하다고 억지로 말하고 억지로 끼위맞춘 부분도 없지
않아 있기는 합니다만, 파일을 다뤄 보셨다면, 위의 예가 오히려 쉽게 오지 않을까
생각합니다. 저도 처음에 위의 예를 들어 설명을 들었을때 쉽게 느껴진듯 하고요.
다음 게시물부터는 실제로 윈도우 소켓을 초기화 해보겠습니다.
이번 게시물에서 특별히 주의할 사항은 없습니다. 단지, 윈도우 소켓이 어떤 형태
고 실제 문법에서 어떻게 사용되는지에 대해 한 번 훓어 보시는 정도면 됩니다.
WinSock을 이용한 네트웍 프로그래밍 #03 지은이 : 정현호
////////////////////////////////////////////////////////////////////////////
// 제 글들은 절대로 상업적 목적으로 사용될수 없으며, 저자인 저의 허락없 //
// 이는 그 어느곳에도 게시를 할 수 없습니다. //
////////////////////////////////////////////////////////////////////////////*
기타 궁금한 사항은 아래로 문의를 바랍니다.
ashulam@hitel.net
ashulam@isoft.co.kr
*윈도우 소켓의 핵심이라 할 수 있는 소켓 초기화 부분에 대해서 다루게 됩니다.
비주얼씨를 가지신분은 MSDN을 참조하시고 윈속 책을 가지신분은 책을 참고 하셔
서
각 함수들의 역할을 분명히 이해해 두셔야만 합니다. C언어의 문법을 배우는 부분
과 비슷하고 중요도도 그와 비슷합니다. ^^;
외워야 하는 부분도 많고 테스트해 볼 부분도 많기에 여러분이나 저나 다 지치겠
군요. ^^;
[예제코드 프로젝트 구성 및 사용법]
이 게시물에 관한 예제는 Network\TCP\Server에 있습니다.
프로젝트에 ws2_32.lib wsock32.lib 파일을 재정의 하셔야합니다.
사용법]
server 서버프로그램의IP주소 서버프로그램의포트번호(2000-65535까지)
실행하시면 어딘가에서의 연결을 기다린다는 메시지만을 출력합니다. 다음 게시물
에서 다룰 클라이언트 프로그램을 실행하시면 연결을 받고 프로그램을 종료합니다.
만일 자신의 IP가 111.222.111.222라면?
server 111.222.111.222 5001
client 111.222.111.222 5001
[윈도우 소켓을 이용한 네트웍 프로그래밍]
*WS2_32.DLL을 초기화해요~
*윈도우 소켓을 만들어 봐요
*바인드가 뭘까??
*누군가의 연결을 기다려 봐요.
*데이터를 보내봐요~~
3. 윈도우 소켓 초기화와 서버 프로그램
이번 게시물은 서버 프로그램에 관한 이야기입니다. 말이 거창하군요. ^^; 보통의
경우 통신시 서버와 클라이언트로 구성이 됩니다. 이번 게시물은 서버를 구동하기
위해 어떤식으로 윈도우 소켓을 초기화하고 나열하는지 보게될 것입니다. 당연히
다음 게시물은 클라이언트겠죠. ^^; 이번 게시물이 아마 전체 게시물중 최고의 중
요도를 자랑한다고 해도 과언이 아닐겁니다. 하나 하나 저도 아는걸 모두 설명할테
니 꼭 꼭 한번씩 타이핑해 보시고 컴파일도 해 보시고 이상하다 싶은건 하나하나
꼭 건들여 보십시요. 정말 중요합니다. 참!! 컴파일이나 소스에 관한 제어는 다음
게시물까지 읽으신후 초기화에 관련된 함수를 잘 보시고 나서 보시는게 좋을겁니다
. 서버와 클라이언트의 전체적인 개념과 두 프로그램의 공통점과 차이점을 확인해
보는 게 중요합니다.
[WS2_32.DLL을 초기화해요~]
윈도우 소켓을 시작하기 전에 윈도우에서 윈도우 소켓과 관련된 DDL파일을 초기화
해 주어야합니다. MSDN에 따르면 WS2_32.DLL를 초기화 한다고 하더군요. 그 과정
은
아래와 같습니다. 거의 아래의 경우를 벗어나는 일은 없을겁니다.
DLL에 관한 설명을 곁들인다.
//WSAStartup()사용하기.-----------------------------------------------------
WSADATA wsaData;
if (WSAStartup(0x202,&wsaData) == SOCKET_ERROR)
{
printf( "WSAStartup설정에서 문제 발생.\n" );
}
소켓에 관련된 함수들을 잘 사용합니다.
WSACleanup();
//WSAStartup()사용하
기.======================================================
윈도우 소켓을 사용하시기 위해 위와같은 과정을 거칩니다.
WSAStartup은 WS2_32.DLL을 초기화 하는 함수입니다.
WSAStartup( 버전, WSADATA구조체의 포인터 );
버전 : 보통 0x202를 씁니다. 거의 디폴트죠. 버전에 관한 인자입니다.
WSADATA의 구조는 아래와 같습니다.
typedef struct WSAData
{
WORD wVersion;
WORD wHighVersion;
char szDescription[WSADESCRIPTION_LEN+1];
char szSystemStatus[WSASYS_STATUS_LEN+1];
unsigned short iMaxSockets;
unsigned short iMaxUdpDg;
char FAR * lpVendorInfo;
} WSADATA, FAR * LPWSADATA;
WSACleanup은 WS2_32.DLL의 사용을 끝내겠다고 알리는 함수입니다.
int WSACleanup( void );
wVersion : 버전입니다.
wHighVersion : 버전입니다. 보통은 wVersion과 같은 값을 갖습니다.
szDescription[WSADESCRIPTION_LEN+1] : 현재 소켓에 대한 설명입니다.
szSystemStatus[WSASYS_STATUS_LEN+1] : 현재 상태를 나타냅니다.
unsigned short iMaxSockets : 나중에 채워지는 값입니다만 2.0이후에는
무시되는 값으로 알고 있습니다.
unsigned short iMaxUdpDg : 2.0이상에서는 사용되지 않습니다.
char FAR * lpVendorInfo: 2.0이상에서는 사용되지 않습니다만, 1.1
버전에서는 사용됩니다. 어디에 쓰이는지
는 저도 모릅니다. ^^;
실제로 뽑아볼 값은 wVersion정도입니다. ^^; 결과는 아래에..... ^^;
Version:202 :버전
HighVersion:202 :버전
Description:WinSock 2.0 :버전을 문자열로 뽑을. -_-;
SystemStatus:Running :현재 윈도우 소켓의 상태를 나타냄.
MaxSocket:0 :2.0이상에는 설정시 무시되는 값. -_-;
MaxUdpDg:0 :1.1에서만 쓰인다는데 어디에 쓰는지 저도 모릅니다.
[윈도우 소켓을 만들어 봐요]
보통 사용법은 아래와 같습니다.
//윈도우 소켓을 만들어 봐요~------------------------------------------------
WSADATA wsaData;
SOCKET ServerSocket; //소켓을 선언합니다.
SOCKADDR_IN ServerAddress; //소켓의 주소 정보를 넣는 구조체입니다.
unsigned short ServerPort = 5001;
if (WSAStartup(0x202,&wsaData) == SOCKET_ERROR)
printf( "WSAStartup설정에서 문제 발생.\n" );
ServerAddress.sin_family = AF_INET; //반드시 AF_INET이어야합니다.
//IP주소값. INADDR_ANY는 아무거나입니다. ^^;
ServerAddress.sin_addr.s_addr = inet_addr( "210.106.224.142" );
ServerAddress.sin_port = htons( ServerPort ); //포트번호
//소켓을 만듭니다. 자세한 설명은 아래에......
ServerSocket = socket(AF_INET, SOCK_STREAM,0); //
if( ServerSocket == INVALID_SOCKET ) //에러 발생시 문구 출력.
{
printf( "소켓을 생성할수 없습니다." );
}
윈도우 소켓 관련 함수들을 잘 씁니다. ^^;
closesocket( ServerSocket ); //소켓을 닫습니다.
WSACleanup();
//윈도우 소켓을 만들어 봐요
~=================================================
SOCKADDR_IN의 구조는 아래와 같습니다.
struct sockaddr_in
{
short sin_family; //AF_INET이어야만 합니다.
unsigned short sin_port; //포트 번호
struct in_addr sin_addr; //IP주소 EX) "169.254.34.243"
char sin_zero[8];//SOCKADDR과 치환할때 같은 사이즈를 만들기
//위해 8바이트의 공란이 있습니다. 무의미.
};
socket()은 소켓을 초기화 하는 함수입니다. 당연한가요? ^^;
SOCKET socket ( int af, int type, int protocol );
af : 주소 계열에 대한 기술. 거의 AF_INET이 디폴트
type : 아래에 구 값중 하나가 들어갑니다.
SOCK_STREAM : TCP프로토콜을 사용할때 씁니다. 양쪽이 확실한 연
결을 해
놓고 쓰는 방식입니다. 전화와 비슷하죠.
SOCK_DGRAM : UDP프로토콜을 사용할때 씁니다. 특정한 연결 없이 그냥 보
내는 겁니다. 우편물을 보내는 방식과 비슷합니다.
protocol : 보통 0을 넣습니다. 저도 의미는 모릅니다. ^^;
closesocket()은 특정한 소켓을 닫는 기능을 합니다.
int closesocket( SOCKET s );
[바인드가 뭘까??]
바인드는 위에서 지정한 IP번호와 포트를 소켓과 연결 지어주는 과정이라고 생각하
시면 됩니다. 파일 포인터를 생각해 보시면 쉬울듯 하군요.
file = fopen( "파일이름", "옵션" ); 이렇게 선언하면 file은 어떤 파일과 그에
대한 접근 방식을 알려줍니다. 바인드도 마찬가지 입니다. 실제 예를 보죠.
if( bind(ServerSocket,(struct sockaddr*)&ServerAddress,sizeof
(ServerAddress)
) == SOCKET_ERROR )
printf( "bind() failed with error %d\n",WSAGetLastError() );
ServerAddress는 앞에서 선언한 내용과 같다고 가정합니다.
즉, IP는 169.254.34.243이고, 포트번호는 5001입니다. 바인후 앞으로 ServerSocke
t은 컴퓨터의 "169.254.34.243"번 IP의 5001포트를 나타내는것과 같습니다. 다시
강조하지만, 파일 열때를 잘 생각해 보세요. 거의 비슷합니다. ^^;
[Listen으로 들어 봐요 -_-;]
서버의 경우 연결을 받아들이는 경우가 많습니다. 연결 신호가 동시에 많이 왔을때
는 특정 버퍼에 저장을 해두고 연결을 해 줘야 하는 경우가 생기게 마련이죠. 소켓
에 그 버퍼의 크기를 지정하는 부분이라 보면됩니다. SOMAXCONN는 그 컴퓨터의
하
드웨어에서 사용가능한 최대의 값을 의미합니다. 디폴트값입니다. ^^;
if( listen(ServerSocket,SOMAXCONN) == SOCKET_ERROR )
printf( "listen함수 설정을 실패했습니다.\n" );
참고로 listen의 두번째 인자에 대한 값은 당연히 최대값을 잡는게 당연한게 아닐
까요? 괜히 작게 잡을 이유는 없죠. 하드웨어가 지원하는 최대값을 넣는건 너무나
당연한 거죠. 위와 같이 쓰는건 당연한거죠. ^^;
[누군가의 연결을 기다려 봐요.]
지금까지의 과정들을 아래에 나열하죠. ^^;
WSAStartup();
socket();
bind();
listen();
연결을 기다려봐요~ <=여기입니다. ^^;
closesocket();
WSACleanup();
이제 서버프로그램은 클라이언트의 접속만을 기다리면 되는겁니다. 그 함수는 다름
아닌 accept입니다!! 실제 코드를 볼까요? ^^;
int AddressSize = sizeof( ClientAddress ); //주
소 크기를 저장하는
//변수.
SOCKADDR_IN ClientAddress; //접속한 클라이언트의 주소 정보를 담을 구조체.
SOCKET ClientSocket; //클라이언트 소켓.
ClientSocket = accept( ServerSocket,(struct sockaddr*)&ClientAddress,
&AddressSize );
SOCKET accept ( SOCKET s, struct sockaddr FAR* addr, int FAR* addrlen );
s : 접속을 받아들일 소켓( 서버의 소켓 )
addr : 접속한 클라이언트의 주소를 담을 구조체입니다.
예를 들어 아래와 같다면......
서버 : "169.254.34.243", port : 5001;
결과는 아래와 같습니다. 접속자의 정보를 얻어오는 겁니다.
ClientAddress.sin_family => AF_INET
ClientAddress.sin_family => 5002
ClientAddress.sin_family => "169.254.34.244"
AddressSize : 주소를 얻어올 구조체의 크기를 넣습니다.
즉, accept로 접속한 클라이언트의 주소와 소켓을 모두 알수 있습니다. 중요한 건
소켁입니다. ^^; 실제로 데이터를 클라이언트로 보낼때 사용하는 함수에 필요한 인
자는 소켓이니까요. ^^; 즉, ClientSocket은 받아들이는대로 연결이 끊어지기 전까
지는 어디에 저장을 해 두어야 한다는 이야기겠죠. ^^;
accept함수가 나온김에 블럭킹과 논 블럭킹에 대한 이야기를 참고로 하겠습니다.
블럭킹은 일종의 무한루프라고 보면됩니다. accept함수가 그런데요. accept함수
를
사용하면 연결이 들어올때까지 더 이상의 진행없이 그곳에 멈춰 버립니다. 그리다
다 연결이 오면 계속해서 진행이 되는거죠. 이런 상황을 블럭킹모드라하고 그 반대
가 논 블럭킹이죠. 그냥 지나가 버리는..... ^^; accept가 그 대표적인 예죠.
이와 같은 함수를 쓰시다가 어? 다운인가? 하는 생각을 하실까봐 노파심에서 이야
기를 합니다.
[데이터를 보내봐요~~]
이제 연결을 위한 기본적인 것이 다 되었습니다. 통신을 위한 서버가 만들어졌고,
어떤 클라이언트에서 누가 연결을 했는지에 대한 답이 나왔습니다. 이제는 보내고
받기만 하면 네트웍의 정말 기본적인 것이 다 되는 겁니다. ^^; 마지막 두 함수는
바로 send(), recv()였던것입니다!! ^^;
int send ( SOCKET s, const char FAR * buf, int len, int flags );
s : 데이터를 받을 소켓. 지금까지의 예를 보면 서버에 접속한 클라이언트인
ClientSocket을 넣으면 좋을듯합니다. ^^; ClientSocket으로 데이터를 보내는
거라고 생각하시면 됩니다.
buf : 실제 보낼 데이터의 버퍼의 포인터
len : 보낼 데이터의 크기.
flags : 옵션입니다만 지금은 그냥 "0"으로 알고 있어주십시요. ^^;
리턴값 : 실제로 보낸 데이터의 바이트수.
int recv ( SOCKET s, char FAR* buf, int len, int flags );
s : 데이터를 받을 소켓. 지금까지의 예를 보면 서버에 접속한 클라이언트인
ClientSocket을 넣으면 좋을듯합니다. ^^; SOCKET s에서 데이터를 받는다고 생
각하시면 됩니다.
buf : 실제 데이터를 받을 버퍼의 포인터
len : 실제 데이터를 받을 버퍼의 크기
flags : 옵션입니다만 지금은 그냥 "0"으로 알고 있어주십시요. ^^;
리턴값 : 실제로 보낸 데이터의 바이트수.
실제 사용을 어떻게 하는지 볼까요?
[Send]
char SendMessage[6] = "Test!";
int SendSize = 6;
int ActualSendSize;
ActualSendSize = send( ClientSocket, SendMessage, SendSize, 0 );
[Recv]
int retval;
char Buffer[999]; //적당히 큰 버퍼를 잡아줍니다.
retval = recv( ClientSocket, Buffer, sizeof Buffer, 0 );
휴우~~ 우선은 여기까지입니다. 정말 소켓의 기본중에 기본만 보신겁니다. ^^;
어때요? 어려운가요? 당연히 처음 보시는분은 외울게 많아서 어렵게 느껴질수도 있
을겁니다만, 하나하나 천천히 잘 보시면 분명히 전부 이해하실수 있을겁니다. 네트
웍에 관한 이론을 잘 이해해 두셨다면 위의 내용들은 이론을 코드로 옮긴것에 불과
하니 잘 따져보시면 어렵지 않게 이해할 수 있을 겁니다.
실제코드는 아래에 있습니다. 꼭 숙지하십시요!!
//서버 코드-----------------------------------------------------------------
#include <stdio.h>
#include <Winsock2.h>
void main()
{
WSADATA wsaData;
SOCKET ServerSocket; //소켓을 선언합니다.
SOCKADDR_IN ServerAddress; //소켓의 주소 정보를 넣는 구조체입니다.
unsigned short ServerPort = 5001;
if (WSAStartup(0x202,&wsaData) == SOCKET_ERROR)
{
printf( "WSAStartup설정에서 문제 발생.\n" );
WSACleanup();
exit( 0 );
}
//반드시 AF_INET이어야합니다.
ServerAddress.sin_family = AF_INET;
//IP주소값. INADDR_ANY는 아무거나입니다. ^^;
ServerAddress.sin_addr.s_addr = inet_addr( "210.106.224.142" );
ServerAddress.sin_port = htons( ServerPort ); //포트번호
//소켓을 만듭니다. 자세한 설명은 아래에......
ServerSocket = socket(AF_INET, SOCK_STREAM,0); //
if( ServerSocket == INVALID_SOCKET ) //에러 발생시 문구 출력.
{
printf( "소켓을 생성할수 없습니다." );
closesocket( ServerSocket );
WSACleanup();
exit( 0 );
}
if( bind(ServerSocket,(struct sockaddr*)&ServerAddress,sizeof(
ServerAddress) ) == SOCKET_ERROR )
{
printf( "바인드를 할 수 없습니다." );
closesocket( ServerSocket );
WSACleanup();
exit( 0 );
}
if( listen(ServerSocket,SOMAXCONN) == SOCKET_ERROR )
{
printf( "listen함수 설정을 실패했습니다.\n" );
closesocket( ServerSocket );
WSACleanup();
exit( 0 );
}
SOCKET ClientSocket;
SOCKADDR_IN ClientAddress;
int AddressSize = sizeof( ClientAddress );
printf( "서버로의 연결을 기다리고 있습니다.\n" );
if( (ClientSocket = accept( ServerSocket,(struct sockaddr*)
&ClientAddress , &AddressSize )) == INVALID_SOCKET )
{
printf( "Accept시 문제 발생.....\n" );
getchar();
}
else
{
printf("접속 IP: %s, 포트 : %d\n", inet_ntoa
(ClientAddress.sin_addr), htons(ClientAddress.sin_port)) ;
}
closesocket( ServerSocket ); //소켓을 닫습니다.
WSACleanup();
printf( "서버 프로그램이 종료 되었습니다.\n" );
getchar();
}
//서버 코드
==================================================================
WinSock을 이용한 네트웍 프로그래밍 #04 지은이 : 정현호
* 지난 시간에는 윈도우 소켓 초기화를 서버 프로그램(?)을 예로 들어 설명을 했었
습니다. 이번 시간에는 클라이언트 프로그램에 대한 이야기를 하려합니다. 서버 프
로그램과 그다지 다를점은 없습니다. 서버에서 listen함수로 접속을 기다렸던 부분
을 클라이언트에서는 connect함수로 접속을 하는 부분이 달라질뿐입니다. 따라서
이번 게시물에서는 그렇게 많이 다룰 내용은 없을듯합니다. 거의다 지난 시간에 사
용했던 함수들과 다를바가 없거든요. ^^; 지난 게시물을 잘 읽으신 분들은 큰 무리
없이 이번 게시물은 그냥 읽고 넘어가는 정도일겁니다.
[예제코드 프로젝트 구성및 사용법]
이 게시물에 관한 예제는 Network\TCP\Client에 있습니다.
프로젝트에 ws2_32.lib wsock32.lib 파일을 재정의 하셔야합니다.
사용법]
Client 서버프로그램의IP주소 서버프로그램의포트번호(2000-65535증 아무거나)
서버의 IP주소와 포트번호는 지난게시물에서 서버프로그램에서 사용했던 인자인
IP와 포트번호와 같은 값을 입력하면됩니다.
만일 자신의 IP가 111.222.111.222라면?
server 111.222.111.222 5001
client 111.222.111.222 5001
[윈도우 소켓을 이용한 네트웍 프로그래밍]
*[클라이언트 프로그램의 구조와 서버 프로그램의 구조는 어떻게 다를까?]
[클라이언트 프로그램의 구조와 서버 프로그램의 구조는 어떻게 다를까?]
아래의 예가 정확한 예라고 말할수는 없습니다만, 클라이언트/서버( 이하 : C/S )
의 대표적인(?) 예라고 할수 있습니다. 대표적인 예 맞나? -_-;
[서버] [클라이언트]
WSAStartup(); WSAStartup();
socket(); socket();
bind(); bind();
listen();
accept(); connect();
send() / recv() send()/recv();
closesocket(); closesocket();
WSACleanup(); WSACleanup();
지난 시간에 다룬 서버와 클라이언트는 크게 다를게 없습니다. 서버의 listen,
listen대신 클라이언트에는 connet가 있을뿐입니다. 다시 한 번 강조 하지만 달라
진 점은 거의 없습니다.
[connect()]
int connect ( SOCKET s, const struct sockaddr FAR* name, int namelen );
s : 설정한 소켓입니다.
name : 연결할 서버의 주소에 대한 정보를 넣은 구조체입니다. ^^;
namelen : sockaddr인자의 크기를 넣으면 됩니다.
리턴값 : 성공적으로 연결이 될 경우 0이 리턴됩니다.
실제 코드를 나열해 보도록 하죠.
//클라이언트 프로그램의 구조를 봐요.----------------------------------------
#include
#include
void main()
{
WSADATA wsaData;
SOCKET Socket; //소켓을 선언합니다.
SOCKADDR_IN ServerAddress; //소켓의 주소 정보를 넣는 구조체입니다.
unsigned short Port = 5001; //포트 번호.
int ReturnVal;
//윈도우 소켓을위한 초기화....
if (WSAStartup(0x202,&wsaData) == SOCKET_ERROR)
{
printf( "WSAStartup설정에서 문제 발생.\n" );
WSACleanup();
exit( 0 );
}
//서버와의 연결을 위한 소켓을 만듭니다.
Socket = socket(AF_INET, SOCK_STREAM,0); //
if( Socket == INVALID_SOCKET ) //에러 발생시 문구 출력.
{
printf( "소켓을 생성할수 없습니다." );
WSACleanup();
exit( 0 );
}
//반드시 AF_INET이어야합니다.
ServerAddress.sin_family = AF_INET;
//IP주소값. INADDR_ANY는 아무거나입니다. ^^;
ServerAddress.sin_addr.s_addr = inet_addr( "210.106.224.142" );
ServerAddress.sin_port = htons( Port ); //포트번호
//지정한 서버로 연결을 해 본다.
ReturnVal = connect( Socket, (struct sockaddr*)&ServerAddress,
sizeof(ServerAddress) );
//ReturnVal이 0이 아니면, 문제가 있는 경우입니다.
if( ReturnVal )
{
printf( "서버로 연결을 할 수 없습니다.\n" );
closesocket( Socket );
WSACleanup();
exit( 0 );
}
else
{
printf( "서버 접속이 성공했습니다.\n" );
}
closesocket( Socket ); //소켓을 닫습니다.
WSACleanup();
printf( "클라이언트 프로그램이 종료 되었습니다.\n" );
getchar();
}
//클라이언트 프로그램의 구조를 봐요.----------------------------------------
앞 서버 프로그램과 달라진 부분만 집중적으로 보시면 좋을 듯합니다.
이상으로 기본적인 클라이언트와 서버의 접속을 마칩니다. 다음 게시물부터는 실제
로 네트웍상에서 데이터를 보내보죠. ^^;
WinSock을 이용한 네트웍 프로그래밍 #05 지은이 : 정현호
*////////////////////////////////////////////////////////////////////////////
// 제 글들은 절대로 상업적 목적으로 사용될수 없으며, 저자인 저의 허락없 //
// 이는 그 어느곳에도 게시를 할 수 없습니다. //
////////////////////////////////////////////////////////////////////////////*
기타 궁금한 사항은 아래로 문의를 바랍니다.
ashulam@hitel.net
ashulam@isoft.co.kr
* 이번장은 윈도우 소켓과는 전혀 관련이 없는 부분입니다만, 꼭 알아 두셔야 할
부분입니다. 바로 쓰레드죠. 이미 쓰레드를 아시는 분이라면 가볍게 넘기시면 될테
고 모르시는 분은 잘 숙지해 두셔야 할겁니다. 쓰레드를 알기에 가장 좋은 방법은
운영체제에 관한 책을 공부해 보시는것입니다만, 시간이 않되시는 분은 부득이하게
아래의 글이라도 읽어두시면 작게나마 도움이 될겁니다. ^^;
[예제코드 프로젝트 구성및 사용법]
이글과 관련된 예제는 Network\Thread에 있습니다. 프로젝트를 특별히 수정할
필요도 없으며 특별한 인자도 없습니다.
[윈도우 소켓을 이용한 네트웍 프로그래밍]
*쓰레드란?
*쓰레드를 만들기.
*쓰레드를 사용한 서버의 접속 처리 부분.
5. 쓰레드( Thread )
지금까지는 여러분과 본 내용은 단지, 특정한 IP와 포트를 가진 서버로 접속을 하
고 연결을 끊는것이 전부였습니다. 이번장에서는 원래 데이터 송수신으로 바로 들
어가려고 했습니다만, 큐 만들기나 윈속 이벤트 처리도 있고해서 쓰레드를 간단히
짚고 넘어가보겠습니다. 진짜 서버를 제대로 만들려면 이 쓰레드 관리가 생명입니
다만, 제 글의 목적은 어디까지나 윈속입니다. 쓰레드를 깊게 다룰수는 없고 윈속
을 사용하는데 문제가 없을 정도로만 보겠습니다. 쓰레드는 여러분께서 직접 공부
를 해 두시는게 좋습니다.
*쓰레드란?
쓰레드를 보기전에 함수 호출과정을 보도록 하죠. ^^;
void main()
{
Function_1();
Function_2();
.
.
Fucntion_N();
}
위의 예를 보면 Function1~N까지의 함수들이 실행된다는 사실은 분석(?)하지 않아
도 누구나 다 아실겁니다. 그 과정도 다 아시겠지만, 한 번 설명하자면......
main함수는 프로그램의 제어권을 Fucntion_1으로 넘기고 Function1은 자신의 내용
을 실행합니다. 전부 실행하고 나면 제어권은 다시 main함수로 돌아오게 됩니다.
다음 중에 바로 보이는 Function_2로 main함수는 다시 제어권을 넘기고 Function_2
함수가 실행되고 제어권은 다시 main으로 돌아오게 됩니다. 그 과정이 Function_N
까지 계속되고 main함수는 종료되게 됩니다. 그럼 쓰레드는 뭐냐? 바로 그걸 설명
하기 위해 위의 과정을 설명한 겁니다. 우선은 쓰레드도 하나의 함수라고 생각하십
시요. 그리고 아래의 과정을 보도록 하죠.
void main()
{
Thread_1();
Thread_2();
.
.
Thread_N();
}
위와같이 쓰레드가 N개 있습니다. main함수가 실행되면, 당연히 프로그램의 제어
권은 main이 가지게 됩니다. 다음 Thread_1을 호출하면, 프로그램의 제어권이 Thre
ad_1으로 넘어가는것이 아니라 제어권은 main에 그대로 남아있고, 독립적인 제어권
을 가진 하나의 함수를 호출하고 main함수내의 제어권은 그대로 유지된다고 보시면
됩니다. 즉, 함수와같이 하나의 흐름을 가지고 갔다왔다하는 구조가 아니라 자신의
제어권은 계속 인정되고 프로그램을 진행하면서 쓰레드를 호출하면 함수들이 살아
있는 상태로 계속 유지되는 겁니다. 위와 같은 경우는 N개의 함수들이 프로그램이
종료될때까지 계속 살아있다고 보시면 됩니다.
도스때 프로그램을 해 보신분이면, 램상주 프로그램을 생각하시면 좋겠고요. 윈도
우 API프로그램을 해 보신분들은 윈도우 프로시져를 생각해 주시면 이해가 조금은
쉽게 되지 않을까 싶습니다.
하지만, 위의 말 몇마디로 쓰레드를 처음 접하시는 분들께서 쉽게 이해하지는 못
하실겁니다. 앞으로 나올 코드를 보며 이해를 하시고, 윈도우 관련책에 짧게 나온
쓰레드에 관한 지식이라도 지속적으로 보다보면 이해를 하실수 있을겁니다. ^^;
그리고보니 Hitel GMA 강좌란에도 쓰레드에 관한 간단한 예가 있으니 참조하시면
도움이 될겁니다. ^^;
*쓰레드를 만들기.
앞에서도 이야기했지만, 쓰레드는 호출하면 프로그램 흐름에 영향을 미치지 않고
계속 살아있는 함수라고 정의했었습니다. 왜 제가 함수라고 정의 했는지는 아래에
기술될 쓰레드의 모양을 보면 아실겁니다. 우선은 형태만 보십시요.
사용 컴파일러 : VC++ 6.0
컴파일 옵션 : Alt+F7을 누른후 프로퍼티 시트중 C/C++을 고른후 Category 항목 콤
보박스를 드랍다운 시킨후 Code Generate를 선택합니다.
Use run-time library의 항목 중 MultiThread라는 단어가 들어가는
항목중 아무거나 선택합니다. 참고로 MultiThreaded를 선택했습니다
//쓰레드 구동 프로그램-------------------------------------------------------
#include
#include
#include
unsigned long __stdcall Thread( void *arg )
{
while( 1 )
{
printf( "in Thread!!\n" );
Sleep( 100 );
}
return 1;
}
void main()
{
unsigned long TempValL;
//프로그램이 종료될때까지 0.1초 간격으로 in Thread라는 문자열을 출력합니
//다.
CreateThread( NULL, 0, Thread, 0, 0, &TempValL );
//쓰레드를 구동한후 제어권이 메인 함수로 돌아왔으면, 아래의 구문이 동작합
//니다. 즉, 아래의 문구가 나오면 현재 프로그램이 Thread()안에 머물고 있지
//않음을 알 수 있습니다.
printf( "In Main.\n" );
//아무키나 누르면 종료합니다.
getchar();
}
//쓰레드 구동 프로그램=======================================================
처음 보시는 함수들을 보겠습니다.
HANDLE CreateThread(
LPSECURITY_ATTRIBUTES lpThreadAttributes, // 보안 속성
DWORD dwStackSize, // 스택 크기
LPTHREAD_START_ROUTINE lpStartAddress, // 쓰레드 함수의 포인터
LPVOID lpParameter, // 쓰레드에 들어갈 인자
DWORD dwCreationFlags, // 쓰레드 생성시 옵션.
LPDWORD lpThreadId // 쓰레드 ID에 대한 포인터.
);
lpThreadAttributes : 쓰레드 핸들에 대한 상속이나 특성을 결정짓는 옵션이라고
하는데 전 NULL을 애용하죠. ^^;
dwStackSize : 쓰레드에 할당될 스택의 크기. 0인 음수면 디폴트값을 설정
해주는데, 불려진 쓰레드와 같은 크기를 잡습니다.
lpStartAddress : 쓰레드의 주소
lpParameter : 쓰레드의 인자값 위의 예중에서는
unsigned long __stdcall Thread( void *arg )에
void *arg인자로 넘어갈 값입니다.
dwCreationFlags : 생성시 바로 생성될것인지 특정한 옵션에 의해 생성될 것인
지를 결정합니다.
lpThreadId : 쓰레드 ID에 대한 포인터.
리턴값 : 쓰레드에 대한 핸들이 리턴됩니다. 쓰레드 생성 실패시엔
NULL이 리턴됩니다.
저도 쓰레드를 깊게 사용해 보지 못해 위에 설명한 내용 모두를 사용하지 못하고
전부 알지도 못합니다. 대부분의 경우 디폴트 설정으로 사용합니다. ^^;
쓰레드를 만드는 방법은 CreateThread말고도 _begintherad, _beginthreadex가 있
습니다. _beginthreadex는 NT(Win2000)환경에서만 작동합니다. 저도 처음에 _begin
threadex 사용했다가 물 많이 먹었었습니다. 윈98에서는 않돌아간다고.... ^^;
*쓰레드를 없애기.
별로 추천하지는 않는 방법이지만, TerminateThread함수입니다. 그 사용법은 아래
와 같습니다. 쓰레드를 만들고 얻은 핸들을 이용해서 쓰레드를 없애는 방법이죠.
HANDLE hThread;
hThread = CreateThread( NULL, 0, Thread, 0, 0, &TempValL );
.
.
.
TerminateThread( hThread, 0 ); //Thread라는 쓰레드를 없앤다.
*BOOL TerminateThread( HANDLE hThread, DWORD dwExitCode );
HANDLE hThread : 쓰레드의 핸들.
DWORD dwExitCode : 쓰레드 종료시 리턴될 값.
리턴값 : 성공시엔 0이 아닌값이 리턴됩니다.
가장 안정적인 방법은 쓰레드도 내부의 조건이 맞지 않을 경우 종료 시키주는 경
우입니다. 위의 예를 보면, while( 1 )이라는 무지막지한 루프안에서 갇혀 헤어나
지 못하고 있습니다만, 쓰레드만을 위한 전역 변수를 만들어 쓰레드를 외부에서 꺼
주는 방법이 좋습니다.
TerminateThread가 왜 않좋으냐? 그 이유는 바로 강제성에 있습니다. 위의 예는
간단히 문자열을 화면에 출력하는게 고작이라 별문제가 되지 않습니다. 하지만 쓰
레드안에서 몇십메가 혹은 그 이상의 메모리를 할당하고 해제하지 않은 상태에서
강제로 종료했다고 생각해 보십시요. 메모리 새는건 불 보듯 뻔합니다. 혹은 일정
한 처리과정을 거치지 않고 중간에 엉뚱한 값을 가진후 결과값을 리턴한다면 올바
른 처리가 되지 않겠죠? 하지만, 위와같이 그 내용이 중간에 강제로 종료해도 별
문제가 되지 않는 상황이라는 점을 확실히 알고 계신다면, 얼마든지 사용해도 좋습
니다. 항상 나쁘다는 것은 아닙니다. ^^;
*쓰레드를 사용한 서버의 접속 처리 부분.
그럼 이제 까지 왜 쓰레드 사용법에 대해서 배웠는지 어디에 쓰레드를 쓸지를 이
제 밝혀야 될 때가 온 듯 하군요. ^^;
쓰레드를 사용한 이유는 바로 윈도우 소켓을 좀 더 깔끔하게 사용하기 위함과 윈
속에 있는 블럭킹모드(무한정 기다리는)로 작동하는 함수 때문입니다.
첫째 깔금한 사용이란 쓰레드로 윈도우 소켓에 들어오는 메시지를 잡아내서 사용
하기 위함입니다. 쓰레드 안에 접속요청/접속끊김/데이터 받기등의 기능을 모두 모
아 넣고 그 메시지에 따라 처리를 해주는 겁니다. 윈도우 프로그램에서 프로시져안
에 키입력이나 마우스 움직임같은 부분에 대한 처리를 넣어 두는것 처럼요. 윈도우
프로그램에서 프로시져는 처리해야할 메시지가 너무 많기 때문에 난잡해 지는 단점
이 있었습니다만, 윈도우 소켓으로 넘어오는 메시지는 많지 않기 때문에 이 방법이
아주 효율적입니다.
둘째는 블럭킹 함수들 때문이죠. 서버 프로그램이 실행되고 해야 할 일이 한둘이
아닌데, accept()함수 하나 실행되면, 연결이 오기전까지는 바로 멈춰 버립니다.
접속에 관한 부분을 외부로 빼 버리면, 즉 쓰레드에 넣고 서버가 해야할 일을 하며
접속이 들어오면 쓰레드에서 처리를 해 버리는거죠.
아래에 바로 그 예를 들겠습니다.
[지금까지의 방식] [쓰레드 사용]
void main() unsigned long Thread( void *arg )
{ {
WSAStartUp() while( 1 )
socket(); {
bind() accept();
listen() 접속에 대한 처리;
}
accept() //무작정 기다림. }
closesocket(); void main()
WSACleanup(); {
} WSAStartUp();
socket();
bind();
listend();
Createthread( Thread );
서버에 관련된 프로그램을 진행.
}
지금은 쓰레드안에 접속에 관한 부분만 있기 때문에 쓸모 없어 보일지도 모릅니다
만, 저 쓰레드안에 소켓이 닫힐때, 데이터가 왔을때등에 대한 처리까지 넣어두면
상황이 달라지겠죠? ^^; 바로 다음 게시물에서 다룰 내용입니다.
다음 시간엔 쓰레드 안에 들어갈 내용들을 좀 더 구체적으로 보겠습니다.
WinSock을 이용한 네트웍 프로그래밍 #06 지은이 : 정현호
* 지금까지는 클라이언트/서버의 초기화및 연결까지를 다루었습니다. 이제 실제로
연결될 두 프로그램 사이에 실제로 데이터를 보내도록하죠. 간단히 send/recv만
알면 되긴 합니다만, 그렇게 간단하지만은 않습니다. ^^; 이번 장에서는 간단히
send/recv가 어떻게 쓰이는지만을 봅니다. 코드의 일부를 뜯어 놓은듯한 즉, 단편
적인 느낌이 들긴합니다만, 실제로 채팅 클라이언트/서버 프로그램을 만드는 마지
막 글에서 모든 부분을 알게 될것입니다. 그러니 너무 조급하게 생각하지 마시고
이번 글은 send/recv시에 패킷이 짤려서 올때 어떻게 처리를 하는지와 send가 불
가능한 상황일때는 어떻게 처리를 하는지정도에 관심을 두고 보심이 좋을듯합니다.
아직은 네트웍 프로그램을 위한 단편적인 지식을 쌓는 단계일 뿐이라는 점을 항상
잊지 말아 주십시요. ^^;
[윈도우 소켓을 이용한 네트웍 프로그래밍]
*[이벤트 메시지를 받아봐요~]
*[send()/recv()와 큐]
6. 윈도우 소켓을 이용한 데이터 송수신.
[이벤트 메시지를 받아봐요~]
이제부터는 통신상에서 어떤 메시지(접속,끊김,읽기)가 발생했을때 그에 맞는 함
수로 대응하는 방법을 보겠습니다. 그 형식은 아래와 같습니다. 우선은 코드를 보
도록 하죠.
WSANETWORKEVENTS event;
WSAEVENT hRecvEvent = WSACreateEvent();
WSAEventSelect( Socket, hRecvEvent, FD_ACCEPT | FD_READ | FD_CLOSE );
while( 1 )
{
Sleep( 10 ); //루프가 10/1000초에 한번씩 동작합니다.
WSAEnumNetworkEvents( Socket, hRecvEvent, &event);
if((event.lNetworkEvents & FD_ACCEPT) == FD_ACCEPT)
{
accept(); //접속을 받아들임.
}
if((event.lNetworkEvents & FD_READ) == FD_READ)
{
recv(); //데이터를 읽어들임.
}
if((event.lNetworkEvents & FD_CLOSE) == FD_CLOSE)
{
closesocket( Socket ); //해당 소켓이 닫혔음.
}
}
대강 감을 잡으신분들은 접속, recv와 closesocket과 관계된 즉, 데이터가 온 경
우와 소켓이 닫힌 경우에 대한 사건이 발생한 경우라는 걸 이미 눈치채셨을지도...
그럼 위와 같이 소켓에 관련된 부분의 처리를 어디에 넣느냐?는 지난 게시물 마지
막에서 accept부분을 쓰레드로 띄웠던 부분이 좋을듯하군요. 즉, 위의 구조는 하나
의 쓰레드안에 넣어두고 접속, 데이터 수신, 소켓닫힘을 감지하는 기능을 가진 소
켓감시자가 되는겁니다. ^^; 사용된 함수를 보도록 하죠.
WSANETWORKEVENTS event; //네트웍 이벤트를 저장할 구조체.
WSAEVENT hRecvEvent = WSACreateEvent(); //윈속 이벤트 오브젝트를 초기화하고
//그 핸들을 넘깁니다.
//특정소켓에서 얻고 싶은 이벤트를 설정합니다.
int WSAEventSelect ( SOCKET s, WSAEVENT hEventObject,long lNetworkEvents );
* s : 이벤트를 얻고 싶은 소켓.
* hEventObject : 윈속 이벤트 오브젝트의 핸들
* lNetworkEvents : 감지하고 싶은 오브젝트를 정의합니다.
리턴값 : 0 이면 올바로 동작한 겁니다.
//특정 소켓에서 이벤트가 발생했는지를 알아봅니다.
int WSAEnumNetworkEvents ( SOCKET s, WSAEVENT hEventObject,
LPWSANETWORKEVENTS lpNetworkEvents );
s : 감시할 소켓
hEventObject : 이벤트와 관련된 핸들
lpNetworkEvents : 에러 기록이나 네트웍에서 발생한 이벤트(접속,송수신,끊김등
)가 저장될 곳.
리턴값 : 0 이면 올바로 동작한 겁니다.
[send/recv와 큐]
*send
이미 앞 게시물에서 send()함수는 한번 다룬적이 있습니다만, 복습을 하죠.
char SendMessage[6] = "Test!";
int SendSize = 6;
int ActualSendSize;
ActualSendSize = send( ClientSocket, SendMessage, SendSize, 0 );
*recv
int ActualRecvSize;
char Buffer[999]; //적당히 큰 버퍼를 잡아줍니다.
ActualRecvSize = recv( ClientSocket, Buffer, sizeof Buffer, 0 );
위와 같아 한쪽에서 send로 보내면 반대쪽에서는 recv로 받으면 됩니다. 당연한
거죠. ^^; 한가지 주의할 점이라면 여러분께서 보낸 크기만큼 끊겨서 데이터가 오
지는 않는다는겁니다. 예를 보죠.
[서버]
send( 5바이트 )
send( 5바이트 )
send( 10바이트 )
[클라이언트]
recv( 5바이트 )
recv( 5바이트 )
recv( 10바이트 )
위와같은 형식이 아니라는거죠. 어느정도의 크기로 모여서 오기 때문입니다.
예를 들면 만약 클라이언트가 10바이트씩 받는다면...
recv( 5바이트 );
다음 5바이트가 오기를 기다린다.
recv( 5바이트 ); 10바이트가 되었으니 온 데이터를 인정한다.
recv( 10바이트 ); 10바이트가 되었으니 온 데이터를 인정한다.
만약 20바이트씩 받는다면?
recv( 5바이트 ) //20바이트가 되지 않았으므로 기다린다.
recv( 5바이트 ) //20바이트가 되지 않았으므로 기다린다.
recv( 10바이트 ) // 20 바이트가 되었으므로 그동안 모인 값을 인정한다.
물론 setsockopt함수를 이용해 오는 족족 받는 방법도 있습니다. 그리고 위의 경
우가 항상 적용되는것은 아닙니다. 일종의 시간 단위로 이루어지는 경우가 대부분
입니다. 그러니까 recv함수가 20바이트씩 받는 구조일때 1바이트씩 19번 보내도 반
응이 전혀 없는냐? 그렇지 않습니다. 지정된 시간내에 20바이트를 채우지 못하면,
그동안 받은 값만을 인정해줍니다. 즉 send와 recv가 항상 1:1로 대응되지 않는 상
황이 발생하기 때문에 보내고 받을 데이터를 임시로 보관해 두었다가 보내주는 큐
가 필요하게 되는거죠. recv에 대한 큐를 어떻게 처리하는지 아래를 보도록하죠.
큐를 만드는 방법도 여러가지가 있겠죠. 아래에 제가 만든 방법말고 다른 방법을
생각해 보심도 좋겠죠. ^^;
unsigned long __stdcall ChannelManagementThread( void *arg )
{
char Buffer[80];
//큐를 위한 배열 적당히 크게 잡아둔다.
char Queue[999];
//현재 큐 안에서의 시작점(위치).
unsigned short QueuePosition = 0;
int retval;
//큐를 초기화한다.
memset( Queue, 0, 999 );
//네트웍 이벤트를 위한 기본설정.
WSANETWORKEVENTS event;
WSAEVENT hRecvEvent = WSACreateEvent();
while( 1 )
{
Sleep( 1 );
//이벤트를 초기화한다.
memset( &event, 0, sizeof event );
//소켓에서 얻고 싶은 이벤트를 초기환한다.
WSAEventSelect( Socket, hRecvEvent, FD_READ );
//소켓에서 발생한 이벤트를 얻어낸다.
WSAEnumNetworkEvents( PlayerSocket, hRecvEvent, &event);
//뭔가 읽을게 있으면? 즉, recv함수를 실행해야하면?
if((event.lNetworkEvents & FD_READ) == FD_READ)
{
//데이터를 읽어본다. 실제 몇 바이트를 읽었는지 retval에
//저장한다.
retval = recv( Socket, Buffer, sizeof Buffer, 0 );
//뭔가 읽은게 있으면?
if( retval > 0 )
{
unsigned short Size;
memcpy( &Queue[QueuePosition], Buffer, retval );
QueuePosition += retval;
while( 1 )
{
//아래는 패킷의 크기를 읽어내는겁니다. 데이터를 보낼때 맨
//앞 2바이트에 읽을 전체 데이터의 크기를 보내는거죠. 앞에
//2바이트에 패킷 전체 사이즈를 보내는 부분은 프로토콜에
//대해서 언급할때 다시 보도록 하죠. 지금은 그냥 넘어가요~
memcpy( &Size, &Queue[0], 2 );
//실제 패킷크기만큼 읽었다면?
if( QueuePosition >= Size )
{
char *Message, ReturnMessage;
Message = (char *)malloc( Size );
memcpy( Message, &Queue[0], Size );
//받은 데이터를 인정하고 그에 따른 처리를한다.
QueuePosition-=Size;
memcpy( &Queue[0], &Queue[Size], QueuePosition );
free( Message );
}
else
break;
}
}
}
}
WSACloseEvent( hRecvEvent );
ExitThread( 1 );
}
휴우.... 단지, 받기하나에 대한 큐 처리인데 젤 길군요. 위의 예도 뭐 그리 좋은
건 아닙니다만, 참고하시고 더 좋은 방법을 생각해 보심도 좋겠죠. ^^;
send도 비슷합니다만, 위와는 조금 다릅니다. 언제 받을지 모르는 경우하고 언제
보낼지를 확실히 아는 경우는 당연히 다릅니다. 생각해 보면 여러가지 방법이 있겠
죠? 현재상태가 전송 가능한 상태인지를 감지하고 전송 가능하면 보내는거죠. 그렇
지 않을시에는 데이터를 큐에 저장해 두었다가 전송이 가능해진 시점부터 큐에서
데이터를 읽어내서 보내주는 것도 하나의 방법이 될겁니다. 앞에서도 이야기했지만
, send/recv 함수가 1:1 대응되는 것도 아니고 원하는 만큼이 보내지는 경우가 아
닐때도 있습니다. send의 경우는 아래와 같이만 해줘도 원하는 만큼을 보내줄수는
있을겁니다. 하지만 전송 가능한 상태인지를 확인해 주면 더 완벽해 질겁니다.
bool SendData( char *SendBuffer, int SendBufferSize, int timeout )
{
int StartTime;
int CurrentTime;
int SendedDataSize = 0;
StartTime = timeGetTime();
while( SendedDataSize <= SendBufferSize )
{
CurrentTime = timeGetTime();
SendedBufferSize += send( SendBuffer, SendBufferSize, 0 );
if( CurrentTime-StartTime < timeout )
{
return false;
}
}
return true;
}
위의 경우는 원하는 만큼 원하는 시간안에 보냈는지를 확인하는 함수입니다. 가능
하면, 현재가 send가능한 상황인지도 파악해서 생각하고 send큐에 그 데이터를 넣
어두는 것도 방법입니다. 처음부터 전송이 가능한지 알고 있다면 굳이 send를 호출
하지 않아도 되기 때문이죠. ^^; 뭐 그건 여러분들께서 설계하기 나름입니다.
보통 send후 다른 소켓 작업때문에 전송이 불가능한 경우는 send함수에서 리턴되는
값은 당연히 SOCKET_ERROR죠. WSAGetLastError()함수를 이용해 어떤 에러였는지를
판단해 봅니다. 그 값이 WSAEWOULDBLOCK(에러라기 보다는 경고죠. 함수가 호출된
순간에 즉시 수행이 불가능해 뒤로 밀린 경우라고 보시면 됩니다.)이면 다시 기다
려 보면 되고 그렇지 않을시엔 거의 연결이 끊긴 경우라고 보면 됩니다만, 에러코
드에 따른 처리를 적절히 해 주셔야 되겠죠? 만약 즉시 수행이 불가능해 뒤로 밀린
경우라면, if((event.lNetworkEvents & FD_WRITE) == FD_WRITE)부분를 네트웍 이벤
트 관리자에 추가하셔서 전송이 가능해진 시점을 알아내고 그때 여러분께서 만든
send 큐에 있는 데이터를 전부 보내버리면 되겠죠. ^^; 위의 Time-Out개념은 보다
는 이 방법이 더 직관적이고 유리할듯 합니다. 실제 이에 대한 예는 마지막 글이
될 채팅 클라이언트/서버 프로그램 제작에서 자세히 다루게 됩니다.
예를 보죠.
void SendData( .., .. )
{
int Result;
Result = send();
if( Result == SOCKET_ERROR )
{
if( WSAGetLastError() == WSAEWOULDBLOCK )
{
//큐에 데이터를 넣어두고 나중에 다시 보냅니다.
}
else
{
//연결을 종료합니다.
}
}
}
send는 위의 두가지 원칙만 잘 지킨다면 큰 무리없이 수행될겁니다.
WinSock을 이용한 네트웍 프로그래밍 #07 지은이 : 정현호
* 이전 강좌까지 잘 읽어오신분들이라면, 기본적인 연결처리및 데이터의 송수신처
리까지는 되었을겁니다. 지금까지 사용된 전송에 관한 처리를 위한 프로토콜은 TC
P였습니다. 거의 디폴트였죠. 이번 장에서 다루게 될 내용은 UDP와 TCP의 다른점
정도와 실제 프로그램시 달리 처리해야 하는 부분들 정도 입니다.
[예제코드 프로젝트 구성및 사용법]
이 게시물에 관한 예제는 Network\UDP\Server,Network\UDP\Client에 있습니다.
프로젝트에 ws2_32.lib wsock32.lib 파일을 재정의 하셔야합니다.
사용법]
server 서버의IP주소 서버의포트번호
사용법
client 서버의IP 서버의포트 클라이언트의IP 클라이언트의포트
만일 자신의 IP가 111.222.111.222라면.
server 111.222.111.222 5001
client 111.222.111.222 5001 111.222.111.222 5002
위와같이하면 됩니다.
[윈도우 소켓을 이용한 네트웍 프로그래밍]
*[UDP란? TCP와의 차이점은??]
*[UDP로 설정을 해요~]
*[sendto/recvfrom]
7. TCP와 UDP의 차이점.
[UDP란? TCP와의 차이점은??]
User Daragram Protocol의 약자죠. 윈도우 소켓에서 사용되는 대표적인 프로토콜
로서 TCP와는 몇가지 차이점이 있습니다만 크게 다른점은 없습니다.
우선 가장 크게 다른점이라면,
첫째, UDP는 TCP와 달리 데이터의 수신에 대한 책임을 지지 않습니다. 즉, 보냈지
만 못 받을 경우가 생길수 있습니다. 또한 전송 순서가 바뀔수도 있습니다.
둘째, 헤더의 크기가 단 8바이트입니다. TCP가 20-24바이트로 알고 있습니다.
셋째, 패킷 단편화가 없습니다.
하나 하나 자세히 설명해보죠.
우선 데이터의 정확한 수신에 대한 책임을 지지 않습니다. 즉, 데이터가 아예 가
지 않을 경우도 있고, 데이터의 순서가 뒤바뀌어 올수도 있습니다. 간단한 예를 들
면....... TCP는 전화와 같고 UDP는 소포와 같습니다. 전화는 상대와 이야기를 하
고자할때 전화를 걸고 그 사람인지 확인을 하고 내용을 전합니다. 반면 UDP는 소포
와 같아서 우체국 사정에 따라서 늦게 보낸 물건이빨리 도착하거나 먼저 보낸 물건
이 나중에도착하는 경우도 있죠. 따라서 UDP 패킷에는 메시지의 순서에 관한 부분
까지 넣어주고 순서를 보정해 주어야하지 않을까 싶습니다. 뿐만 아니라 운송도중
에 분실될 경우도 있다고 합니다만, 개인적으로 프로그램을 하기에 치명적일 정도
로 않오는 경우는 없었던것 같습니다. 대부분 받았던것 같은 느낌입니다. ^^;
패킷의 헤더 크기가 작다는 점은 아주 중요합니다. 즉, TCP의 경우에 1바이트를
보낸다면 그 크기에 헤더(송수신위치및 옵션들)크기를 더해서 21-25바이트가 되는
셈이죠. 단 1바이트지만 지속적으로 보내야하는 경우엔 큰 부담이됩니다. 하지만,
UDP는 헤더가 단 8바이트뿐입니다.
패킷 단편화가 없다는 이야기는 앞에서 send/recv함수를 사용하기 위해 큐를 만들
었었죠? 패킷을 보낼때 send/recv가 1:1로 대응되는게 아니라 적당한 크기로 끊겨
오기에 큐를 만들었었습니다. 하지만 UDP에는 이 작업이 필요없습니다. sendto/
recvform함수가 각각 1:1로 대응을 된다는 사실이 밝혀지는군요. 당연한 이야기겠
지만, 패킷의 순서가 뒤바뀌어 올지도 모르는데, 패킷까지 잘려서 온다면...... ^^
TCP와 비교했을때 나름대로 장단점이 있습니다. 위의 내용들을 잘 분석해 보시면
한가지 결론이 나올겁니다. 그건 바로!! 자주보내야하는 데이터에는 UDP를 쓴다.
어쩌다가 한두번 잃어버려도 상관없는 데이터는 UDP로 보낸다. 반면, 중요한 데이
터는 TCP로 보낸다. 이런 결과가 나오는군요. ^^;
[UDP로 설정을 해요~]
기존의 TCP설정 : socket( AF_INET, SOCK_STREAM, IPPROTO_TCP );
새로운 UDP설정 : socket( AF_INET, SOCK_DGRAM, IPPROTO_UDP );
위의 설정이 전부입니다. ^^;
[프로그램 구조는 어떻게 바뀌나요?]
비교를 쉽게 하기위해 기존의 TCP구조와 새로운 UDP구조를 연속적으로 그려내겠습
니다.
~TCP 처리 방식
-서버- -클라이언트-
WSAStartup(); WSAStartup();
socket(); socket();
bind(); bind();
listen();
연결 확립
accept(); <--------------------> connect();
송신/수신
send() / recv() <------------> send()/recv();
closesocket(); closesocket();
WSACleanup(); WSACleanup();
~UDP 처리 방식
-서버- -클라이언트-
WSAStartup(); WSAStartup();
socket(); socket();
bind(); bind();
송신/수신
sendto()/recvfrom() <----------> sendto()/recvform()
closesocket(); closesocket();
WSACleanup(); WSACleanup();
대부분의 구조나 함수들이 이전에 TCP로 여러분들과 구현해온것과 크게 다를게 없
습니다. 단지, socket함수 설정시 들어가는 인자가 바뀌었다는 점 하나하고 send/
recv가 sendto/recvfrom이라는 함수로 대체되었을뿐입니다.
[sendto/recvfrom]
int sendto( SOCKET s, const char FAR * buf, int len, int flags,
const struct sockaddr FAR * to, int tolen );
s : 소켓
buf : 보낼 데이터가 저장된 버퍼.
len : 보낼 데이터의 바이트 크기.
flags : 플래그(옵션).
to : 데이터를 보낼 곳의 주소를 저장한 구조체의 포인터.
tolen : 데이터를 보낼 곳의 주소를 저장한 구조체의 바이트 크기.
int recvfrom ( SOCKET s, char FAR* buf, int len, int flags,
struct sockaddr FAR* from, int FAR* fromlen );
s : 소켓
buf : 받은 데이터가 저장될 버퍼.
len : 받은 데이터의 바이트 크기.
flags : 플래그(옵션).
from : 데이터를 보낸 곳의 주소를 저장할 구조체의 포인터.
fromlen : 데이터를 보낸 곳의 주소를 저장할 구조체의 바이트 크기.
아래의 코드들이 도움이 되겠군요.
struct sockaddr_in ServerAddress;
unsigned short ServerPort;
//IP주소값. INADDR_ANY는 사용가능한 IP 아무거나 입니다. ^^;
ServerAddress.sin_family = AF_INET;
ServerAddress.sin_addr.s_addr = inet_addr( "특정 IP주소" ); //IP주소
ServerAddress.sin_port = htons( ServerPort = "특정 포트번호") ); //포트번호
char Buffer[80];
int BufferSize=80;
int AddressSize = sizeof( ServerAddress );
int RecvSize = 0;
memset( Buffer, 0, sizeof Buffer );
sendto( ClientSocket, "Client Message", 15, 0,
(struct sockaddr *)&ServerAddress, AddressSize );
RecvSize = recvfrom( ClientSocket, Buffer, BufferSize, 0,
(struct sockaddr *)&ServerAddress, &AddressSize );
printf( "받은 메시지 : %s, 받은 메시지 크기 : %d\n", Buffer, RecvSize );
기존에 사용하던 send/recv 방식들과 크게 다를게 없습니다. 단지 사용하던 함수
의 이름이 바뀌었고 그 인자가 바뀌었을 뿐입니다. 정리하자면 socket함수의 인자
가 바뀐점과 send/recv대신 sendto/recvform을 사용한다는 점뿐입니다. 소켓 초기
화의 순서가 좀 달라졌다는 점하고요. ^^;
실제 코드들을 보면서 그리고 참고 문서들을 보면서 정리를 해 보시면 차이점을
어렵지 않게 찾아낼 수 있을겁니다.
WinSock을 이용한 네트웍 프로그래밍 #08 지은이 : 정현호
* 이전까지는 단지 보내고 받는 방법에 대해서만 언급이 있었습니다. 이번에는 그
보내지는 내용을 어떻게 설계해야하는지에 대해서 알아보도록하죠.
[윈도우 소켓을 이용한 네트웍 프로그래밍]
*[프로토콜과 설계]
*[암호화]
*[압축화]
[프로토콜과 설계]
Protocol은 간단히 말해 통신 규약입니다. 송수신자 양쪽에서 어떤 정해진 약속
에 의해 데이터를 보내고 받는거죠. 어떤 예가 좋을까요? 전화를 예로 든다면, 전
화를 걸기 위해서 지켜야 하는 몇가지 규약이 있습니다.
* 다른 지역에 있는 사람이라면 전화 번호 앞에 지역번호를 넣고 그렇지 않으면
지역번호가 필요없다.
* 전화번호는 숫자로만 이루어진다.
* 특정한 전화번호(112,114,119등)는 이미 예약되어 있다.
등등......
위와같은 모두가 알고 있고, 지켜야만 통신이 가능한 사항들이 있습니다. 이런것
들을 바로 프로토콜이라고 생각하시면 간단할겁니다.
이제 여러분과 저도 데이터를 주고 받는 부분에 대한 문제는 어느정도 해결이 된
상태입니다. 이제는 그 데이터를 어떻게 주고 받을지에 대한 설계를 해야할때가 되
었습니다. 우선은 제가 쓰던 방식을 아래에 기술하겠습니다. 실제로 아래의 방식은
저 말고도 다른 개발자들도 많이 사용하는 기본 구조라고 알고 있습니다.
?바이트 : 패킷의 전체크기( ?바이트+?바이트+(나머지+?) )
?바이트 : 패킷의 성격
나머지+? : 패킷의 내용.
저는 위와 같은 형태로 데이터를 보냅니다. TCP의 경우 패킷이 잘려서 도착을 하는
경우가 있기 때문에 처음엔 전체 크기를 넣어 recv함수가 읽어야 할 전체 크기를
정합니다. 다음은 그 패킷의 성격을 보냅니다. 예를 들면 1은 패스워드. 2는 공격
신호 이런식이죠. 그 뒤에 붙은 데이터는 실제 데이터입니다. 실제 패스워드나 공
격 신호일 경우엔 누가 누구에게 몇의 데미지를 입혔는지? 이런식입니다.
위의 방식은 지극히 단순한 방법입니다. 몇가지를 더 추가해야 하는데 그것은 여
러분들의 몫입니다. 간단히 생각해 낼 수 있는 방법은 암호화와 압축일 것입니다.
[암호화]
암호화도 따지면 꽤 다양한 방법이 있습니다.
예를 들자면 코드 대조법, 시프트, 특정값 가감연산등등....
코드 대조법 : 코드표를 보고 원래 값을 찾아내는 방법입니다.
[ !^^7Q ] 이와 같은 코드가 있고 코드표에 치환코드가 있는거죠.
! = A
^ = P
^ = P
7 = L
Q = E
위와같이 풀어내는 방법입니다.
시프트 : APPLE를 좌우로 몇칸 이동 시키는 방법이 있습니다.
PPLEA, PLEAP, LEAPP, PPLEA와 같이요.
특정값 가감연산 : 말 그대로 컴퓨터에서 사용되는 문자들이 사실은 숫자라는 사실
을 이용하는 겁니다. 예를 들면 A = 65죠. 이값에 ?값을 더한다
거나 ?값을 뺀다거나 등등의 방법을 이용해서 새로운 값을 만들
어 주고 원래 값으로 복원을 할때는 그 반대 방법을 쓰는겁니다
그외에 패킷에 특정 마스크를 이용한 비트 연산(And, Or, Xor)을 해 주는 방법도
있습니다. 그리고 특정한 주기마다 암호화 패턴을 바꾸어 주는 방법도 생각해 볼
수 있습니다.
[압축화]
압축화는 패킷의 내용을 보호한다는 측면과 실제 패킷을 줄인다는 두가지 측면에
서 아주 유용한 패킷 처리방법입니다. 무손실 압축법인 RLE, LZW방식을 애용함이
좋을듯합니다만, 이렇게 되면, 압축 패킷을 줄이는 목적을 달성할 수는 있지만, 패
킷 노출이라는 문제는 피할수 없게 될 것입니다. 기존에 나온 압축법을 적절히 활
용해 자신만이 사용하는 압축 기술을 개발하는 것도 하나의 과제가 될 것입니다.
앞에서 암호화와 압축화를 이야기한것은 보안문제 때문입니다. 몇년전 부터 해킹
기술이 프로그램화되어 나왔기 때문에 네트웍을 잘 모르는 사람도 해킹 프로그램만
다룰줄 안다면 해킹이 가능한 시대로 접어들었습니다. NetSpy, NetXRay같은 프로그
램을 잠깐 봤는데, 특정 송수신 IP만 집어주면 그 사이에서 송수신되는 모든 데이
터가 그대로 노출이 되더군요. 게다가 원하는 코드를 걸러서 보여주는 기능도 있기
때문에 아무리 패킷양이 많아도 원하는 데이터를 얼마든지 쉽게 걸러서 볼 수 있게
만들어졌습니다. 이런 상황에서 여러분들의 송수신 데이터에 대한 보안 문제는 당
연한 일이 될 것입니다. 이 문제는 여러분들께서 풀어야 할 문제입니다.
WinSock을 이용한 네트웍 프로그래밍 #09 지은이:정현호
이제 제 글도 막바지에 이른듯합니다. 특별히 새로울것은 없습니다. 단지,
지금까지 해왔던 여러가지들을 어떻게 묶는지만을 보여주는 정도입니다. 지금까지
의 내용을 잘 이해하신 분이라면 가볍게 이해하실수 있으리라 봅니다. 그럼
시작하죠.
[예제코드 프로젝트 구성및 사용법]
이글과 관계된 프로젝트는 chat\server, chat\client입니다. 설명은 서버에 관련
된 부분만 하겠지만, 기본적으로 클라이언트/서버의 구조가 90%이상 같고 다른
부분 10%는 이미 앞에서 언급을 했기 때문에 더 이상 업급하지 않을것입니다. ^^;
두 프로젝트에 포함된 ws2_32.lib wsock32.lib 파일을 재정의 하셔야합니다.
만일 자신의 IP가 111.222.111.222이면?
server 111.222.111.222 5001 <-(포트번호 5001은 임의로 잡았습니다.)
client 111.222.111.222 5001 <-(서버에 접속하기 위해 포트 번호를 5001로....)
우선 서버쪽에서 프로그램을 실행 시켜놓고 클라이언트의 접속을 기다립니다. 클
라이언트와 연결이 성립되면, 채팅이 가능해집니다. 종료 명령어는 /q,/Q이며
어느 한쪽의 연결이 끊어지면 양쪽의 연결이 끊어집니다.
특별히 별 기능은 없고 어찌보면 아주 초라한 프로그램입니다. 하지만 기본에서만
은 볼 부분이 그럭저럭 있다고 생각합니다. 단순히 1:1의 채팅이지만 조금만 손을
보면 n:n의 채팅도 가능합니다. 또한 조금만 생각을 하시면 로비서버나 좀 더 세련
된 서버를 생각해 내실수 있을겁니다. 항상 이야기하지만 제가 여러분께 제공해
드린 것은 가이드라인이지 어떤 정형화된 형태가 아닙니다. 그 가이드라인에 문제
가 많기는 합니다만...... ^^;
[윈도우 소켓을 이용한 네트웍 프로그래밍]
*[SendQueue]
*[소켓 이벤트 관리 쓰레드 생성]
*[채팅 메시지를 위한 패킷만들기]
*[send/recv시 큐를 이용함]
[서버 프로그램의 구조]
우선은 전체적인 구조를 보도록 하죠.
1. 소켓초기화 및 접속 요청을 기다림.
2. 서버 네트웍 이벤트 관리 스레드 활성화.
3. 채팅 메시지 교환.
4. 프로그램 종료.
위의 내용이 전부입니다. ^^; 하나 하나 뜯어 보도록하죠.
chat\server\server.cpp파일을 열어 보도록하죠. 그리고 main함수를 보겠습니다.
기존의 코드와 크게 다른부분이 몇몇 눈에 보이는군요. 정리하면......
1. SendQueue
2. 소켓 이벤트 관리 쓰레드 생성.
3. 채팅 메시지를 위한 패킷만들기.
4. send/recv 큐
대강 위에 언급한 정도입니다.
[SendQueue]
제가 만든 Send Queue 구조체입니다. 그 구조는 아래와 같습니다.
#define SendQueueSize 999
struct tag_SendQueue
{
int CurrentPos;
int DesPos;
int PacketSize[SendQueueSize];
char *Packet[SendQueueSize];
} SendQueue;
CurrentPos : 현재 큐의 위치.
DesPos : 현재 쌓인 큐의 위치.
PacketSize : 보내지 못하고 큐에 쌓인 패킷의 크기.
Packet : 보내지 못한 패킷의 내용.
이미 여섯번째 글에서 언급했던 내용이죠. send/recv시엔 큐를 만들어서
데이터의 송수신시 발생할수 있는 문제를 해결한다는 부분을 구체화하기
위해서 만든 큐입니다. 구조체의 이름 그대로 send시에 패킷을 보내지
못할 경우를 대비해서 만들었습니다. 조금 더 읽어 나가시면 그 쓰임을
알게 됩니다.
[소켓 이벤트 관리 쓰레드 생성]
여기에도 한 가지가 추가되었습니다. ServerProcessThread를 보게 되면
FD_WRITE라는 네트웍 이벤트가 새로 추가되었습니다. FD_WRITE는 send가
가능하다는 신호를 받아 내는겁니다. FD_WRITE는 connect후(즉 상대 네
트웍에 연결후)와 send가 가능해진 시점에서 발생합니다. 즉, send가
가능한지를 판단하기 위해서 필요합니다. 실제 코드를 보도록하죠.
//Sendable는 send가 가능한지 판별하기 위한 전역 변수입니다.
if ((event.lNetworkEvents & FD_WRITE) == FD_WRITE)
{
Sendable = true;
}
[채팅 메시지를 위한 패킷만들기]
우선 제가 쓰는 클라이언트/서버의 패킷 구조를 보겠습니다.
2바이트 : 패킷의 전체크기.
1바이트 : 패킷의 성격.
나머지 : 패킷의 내용.
만약 패킷의 성격이 아래와 같이 정의되어 있는데, 채팅이며, 그 내용이
"안녕하세요?"일때 패킷은 어떻게 구성이 될까요?
#define Packet_Chat 0x00 //채팅.
#define Packet_RequestUserInfo 0x01 //유저의 정보를 요구한다.
#define Packet_Attack 0x02 //공격신호
#define Packet_UseItem 0x03 //아이템을 쓴다.
바이트 내용
2 15(10진수)
1 Packet_Chat == 0
12 안녕하세요?\0
위와 같습니다. 패킷의 구조에 관해서 이야기를 하긴 했지만 구체화 하긴
이번이 처음인것 같습니다. ^^; 그럼 실제 패킷을 만들고 보내는 코드를
보죠.
*MsgBuffer안에 채팅 내용이 들어 있다고 가정을 하죠.
int MsgSize;
char *Packet = NULL;
MsgSize = strlen( MsgBuffer ); //채팅 내용의 길이를 알아냅니다.
MsgSize+=3; //패킷의 길이, 패킷의 성격값까지 더해서 실제 패킷
//의 길이를 구합니다.
Packet = (char *)malloc( MsgSize ); //패킷의 크기만큼 메모리확보.
memcpy( &Packet[0], &MsgSize, 2 ); //패킷의 길이를 처음 2바이트에...
memset( &Packet[2], Packet_Chat, 1 ); //패킷의 성격을 다음 1바이트...
memcpy( &Packet[3], MsgBuffer, MsgSize-3 ); //실제 내용을 마지막에...
SendPacket( Packet, MsgSize ) //패킷을 보냅니다. sendpacket함수는
//바로 다음절에 설명하겠습니다.
free( Packet ); //패킷을 다 보냈으면 할당한 메모리를 해제합니다.
[send 큐]
오늘의 핵심인 send/recv큐에 관한 설명이군요. 우선 SendPacket함수를
보도록하죠. 이미 여섯번째 글에서 언급을 했듯이 send를 한다고 무조건
전송되는건 아닙니다. 당연히 그럴 경우엔 데이터를 송신자 컴퓨터에
저장했다가 send가 가능한 상황이 되면 저장된곳의 데이터를 참고해서
보내주어야합니다. 이미 그 상황과 사용법은 여섯번째 글에서 언급했으
므로 더 이상언급하지 않겠습니다. 다만, 어떻게 코딩을 해야하는지를
보겠습니다.
send가능한 상황인지 판단을 합니다.
if( Sendable == true ) //send가능하면...
{
현재 큐를 확인해서 못보낸 패킷이 있으면 보낸다. 보내는중에 send
불가능 상황이 발생하면 그곳에서 멈추고 보낼 패킷은 큐에 넣는다.
bool Processed = false;
Processed = ProcessQueue();
send가능한 상황이면?
send함수로 데이터를 보내봅니다. 만약 문제가 발생하면 큐에 패킷을
넣고 아니면 데이터를 송신을 완료합니다.
send불가능한 상황이면?
패킷을 큐에 넣습니다.
}
else //send가 불가능한 상황이면?
{
패킷을 큐에 넣습니다.
}
다른분들은 어떻게 하는지 모르겠습니다만, 저는 위와같은 방법을 생각했습니다.
실제 코드로는 어떻게 적용되는 보겠습니다. 코드 중간에 나오는 ProcessQueue
와 InsertQueue함수는 다음 절에서 보겠습니다.
if( Sendable == true )
{
//큐를 확인해본다. 있으면 보낸다. 다 보낼수 있을때 까지 보내본다.
//만약 못 보내면 Packet은 또 큐에 넣는다.
bool Processed = false;
Processed = ProcessQueue(); //큐에 더이상 보낼 패킷이 남아있지
//않으면 true리턴
if( Processed == true ) //큐에 아무것도 남아 있지 않으면?
{
TotalSendSize = 0;
if( Sendable == true ) //전송이 가능한 상황이면?
{
while( 1 )
{
SendSize = send( MyClient.ClientSocket, Packet, MsgSize, 0 );
if( SendSize == SOCKET_ERROR ) //send시 문제발생
{
int Error = WSAGetLastError();
if( Error == WSAEWOULDBLOCK ) //소켓함수가 즉시 실행될수 없는
//상황. 즉, send함수가 수행될수
//없는 상황입니다.
{
printf( "큐에 데이터를 넣습니다.\n" );
Sendable = false;
InsertQueue( Packet, MsgSize, TotalSendSize );
break;
}
else //소켓함수가 즉시 실행될수 없는 상황이 아니면 거의 접속이
//끊긴 경우이므로 프로그램을 종료합니다.
{
BreakFlag = true;
break;
}
}
else
{
TotalSendSize += SendSize;
if( TotalSendSize >= MsgSize )
{
SendSucceeded = true;
break;
}
}
}
}
else //if Sendable == false
{
InsertQueue( Packet, MsgSize, TotalSendSize );
printf( "큐에 넣겠습니다.\n" );
}
}
else //if Processed == false 큐에 남은 패킷을 보내는중 send불가능
//상황이 발생.
{
InsertQueue( Packet, MsgSize, TotalSendSize );
printf( "패킷을 보내지 못했습니다. 큐에 넣겠습니다.\n" );
}
}
else //if Sendable == false
{
InsertQueue( Packet, MsgSize, TotalSendSize );
printf( "패킷을 보내지 못했습니다. 큐에 넣겠습니다.\n" );
}
[ProcessQueue / InsertQueue ]
*InsertQueue
큐삽인 함수는 send실패시에 프로그램에서 만들어둔 구조체에 패킷을 넣는 함수
입니다. 패킷의 내용, 크기, 보낸 패킷의 크기를 인자로 받습니다.
int InsertQueue( char *Packet, int MsgSize, int TotalSendSize )
{
//큐에 패킷을 저장하기 위해 메모리를 할당합니다.
if( SendQueue.Packet[SendQueue.DesPos] != NULL)
{
free( SendQueue.Packet[SendQueue.DesPos] );
SendQueue.Packet[SendQueue.DesPos] = NULL;
}
SendQueue.Packet[SendQueue.DesPos] = (char *)malloc
( MsgSize - TotalSendSize );
//할당된 공간에 보내지 못한 패킷을 저장합니다.
memcpy( SendQueue.Packet[SendQueue.DesPos], &Packet[TotalSendSize],
MsgSize - TotalSendSize );
//패킷의 크기를 저장해둡니다.
SendQueue.PacketSize[SendQueue.DesPos] = MsgSize - TotalSendSize;
//큐에 저장된 패킷의 위치를 증가시킵니다.
SendQueue.DesPos++;
//999가 되면 0으로 반복되는 일종의 순환큐입니다.
if( SendQueue.DesPos >= 999 )
SendQueue.DesPos = 0;
return 1;
}
*ProcessQueue
SendQueue구조체를 참조해서 보내지 못한 패킷이 있으면 보냅니다.
[recv 큐]
이미 여섯번째 글에서 언급했듯이 recv 또한 send처럼 네트웍상에서 일정한
크기로 잘려올수 있기 때문에 큐를 만들어 두어야합니다.
//받을 데이터가 있으면?
if ((event.lNetworkEvents & FD_READ) == FD_READ)
{
//데이터를 받아본다.
retval = recv( MyServer.ServerSocket, Buffer, sizeof Buffer, 0 );
if( retval > 0 ) //만약 몇 바이트라도 받았으면?
{
//큐에 데이터를 넣어둔다.
unsigned short Size;
memcpy( &Queue[QueuePosition], Buffer, retval );
QueuePosition += retval;
while( 1 )
{
//패킷의 구조에 따라 처음 2바이트(패킷의 크기만큼)를 받으면,
//인정을 하기위해 전체 크기를 알아둔다.
memcpy( &Size, &Queue[0], 2 );
//전체 크기만큼 받았으면?
if( QueuePosition >= Size )
{
char *Message=NULL;
char ReturnMessage;
Message = (char *)malloc( Size );
memcpy( Message, &Queue[0], Size );
//완전히 패킷을 받았으면, 그 패킷을 적절히 처리를한다.
ReturnMessage = ProcessClientMessage( Message );
QueuePosition-=Size;
memcpy( &Queue[0], &Queue[Size], QueuePosition );
free( Message );
}
else
{
break;
}
}
}
}
한가지 설명이 빠진듯하군요.
ReturnMessage = ProcessClientMessage( Message );
바로 위 부분입니다. 완전히 패킷을 받았을때 그 패킷을 처리하는 함수를
만들어 두는겁니다. 그 내용을 보죠.......
//패킷에 관한 정의들......
#define Packet_Chat 0x00 //채팅.
#define Packet_RequestUserInfo 0x01 //유저의 정보를 요구한다.
#define Packet_Attack 0x02 //공격신호
#define Packet_UseItem 0x03 //아이템을 쓴다.
int ProcessClientMessage( char *Message )
{
if( Message[2] == Packet_Chat ) //채팅 메시지.
{
char *MsgPtr = &Message[3];
printf( "서버 : %s\n", MsgPtr );
}
return 1;
}
현재는 채팅 메시지에 관한 처리만이 있습니다만, 실제 채팅 프로그램을 만들다
보면 더 많은 패킷의 성격이 필요할것입니다. 그 부분에 관한 정의는 여러분들이
추가를 하시면 됩니다. 그리고 ProcessClientMessage안에 추가해 주시면 되겠죠?
이미 앞에서도 언급했지만 클라이언트 프로그램도 따로 분석을 하려했습니다만
지금까지 게시된 모든 글을 이해하셨다면, 특별한 설명이 없어도 될 것 같습니다.
어찌어찌하여 글은 다 완성을 했습니다만, 아쉬움이 크네요. 시간에 쫓기고 몸도
피곤하고 물론 정신력으로 해결하면 되는 부분이긴 하지만 잘 되질 않았네요. 그래
서 더 아쉬운지도 모르겠습니다. 솔직히 네트웍은 잘 하는 부분도 아니고 관심밖
분야이기 때문에 이 글을 올려야할지에 대해서 많이 생각을 했습니다. 네트웍 프로
그램의 중요한 개념을 많이 언급하지 못한것도 사실이고요. 물론 이런 말로 면죄부
를 받겠다는 것은 아닙니다. 단지, 아쉬움을 표할뿐이죠. ^^; 제 글이 네트웍 프
로그램을 시작하는 분들께 작게나마 도움이 되었으면 좋겠습니다.
--------------------------------------------------------------------------------
TCP/IP를 기반으로한 온라인 게임 제작
--------------------------------------------------------------------------------
최근들어 온라인 게임들이 점점 대중화되며 인기를 끌고 있다. 특히 수천 명이 하나의 서버에서 게임 내 가상스페이스를 공유하며 플레이하는 그래픽 머드의 개발과 동작원리는 게임 개발을 시작하려는 사람들에게 많은 관심의 대상이 되고 있다. 3부에서는 간단한 그래픽 머드의 서버와 클라이언트 프로그램을 구현하고 이를 통해 그 구조를 살펴본다.
온라인 게임과 싱글유저 게임은 사실 별다른 차이점이 없다. 이를 RPG로 한정하고 생각한다고 해도 유일하게 다른 점은 한가지뿐이다. 현재 내가 플레이하고 있는 게임의 여러 자원들, 즉 게임 내의 나의 분신인 게임 캐릭터와 캐릭터가 싸우고 있는 게임 속의 몬스터, 캐릭터가 가지고 있는 아이템, 옆을 걸어 지나가는 마을주민 등이 게임이 플레이 중인 자기 PC에 있는냐 아니면 랜이나 전화선으로 연결된 온라인 상의 어느 곳에 존재하느냐 일뿐이다.
그러나 이러한 멀티유저 게임과 싱글유저 게임의 차이점은 게임제작에서 실제 개발뿐만이 아니라 기획단계부터 많은 제약을 받게 된다. 싱글유저라면 간단하게 만들 수 있는 RPG의 퀘스트도 멀티유저 온라인 RPG라면 엄청난 일이 된다.
예를 들어 뒷산에 있는 어떤 보스급 몬스터를 죽이면 꽤 좋은 아이템을 주는 이벤트를 만든다고 할 때 싱글유저 게임이라면 별 문제가 아닐 수도 있지만 멀티유저 게임이라면 문제가 틀리다. 같은 게임을 플레이중인 플레이어가 한 명이 아니라 수백 또는 수천 명이 될 수도 있기 때문에 몬스터가 주는 아이템이 좋을 경우 한 명의 용감한 용사가 아니라 수백 명이 말 그대로 인해전술로 몬스터 한마리를 잡기 위해 몰려들 수도 있다. 이럴 경우 그 몬스터는 당연히 몇 분만에 제대로 싸워보지도 못하고 죽게 될 것이고, 플레이어의 숨막히는 모험을 기대한 기획자의 기획은 실패하게 된다. 멀티유저게임은 이런 기획상의 문제를 극복한다고 해도 실제 개발에서 해결해야할 문제가 많이 남아있다.
동기화 (Synchronization)
멀리 떨어져 있는 많은 게임 플레이어들이 하나의 가상 공간에서 같은 게임을 즐긴다는 것은 분명히 매력적이기는 하지만, 개발자에게는 많은 골치거리를 제공한다. 게이머들이 모두 동일한 환경에서 빠른 네트워크를 통해 게임에 접속해서 게임을 플레이한다면 좋겠지만 불행히 현실은 그렇지 않다. 어떤 사람은 T3 이상의 고속회선을 통해서 게임을 할 수 있고 또 다른 사람은 1400bps의 느린 모뎀에 낮은 클럭의 486PC에서 게임을 할 수도 있다. 이런 상이한 조건의 클라이언트들에게 ‘거의’ 동일한 서비스를 제공하기 위해서는 많은 테크닉이 필요하다.
해킹
그래픽 머드의 특성상 게임 내의 실제 데이터는 로컬 PC에 존재하게 된다. 로컬 PC에 있는 데이터를 분석하고 조작해서 게임을 편하게 즐기는 단순한 해킹에서부터 TCP/IP의 하위 레이어에 침투해서 패킷을 가로채 분석한 다음 가짜 패킷을 서버에 보내는 전문 해커까지 서버를 공격하는 방법은 다양하다. 개발자는 패킷을 암호화하거나 게임 데이터를 압축해서 이러한 해킹에 대항해야 한다.
서버의 안정성
훌륭한 기획에 그래픽을 만드는 것까지는 순조롭게 진행이 되다 결국의 서버의 안정성이 확보되지 않아 개발이 실패하는 일도 발생할 수 있다.
싱글유저 게임이라면 이런 문제에 대해 걱정할 필요가 없겠지만, 메가 플레이어가 접속하는 게임이라면 네트워크 문제(이것은 일단 돈으로 해결할 수도 있다)와 수십 개의 스레드를 사용할 때 발생하는 데드락, 시스템 정지, 메모리 참조에러 등 오래 살아있는 서버를 만드는 것이 게임 자체를 만드는 것보다 오히려 어려울 수도 있다.
양질의 회선
네트워크 게임은 대부분 리얼타임으로 게임이 진행되고 서버/클라이언트 사이에 주고받는 데이터의 양은 다른 서비스와 비교할 수 없을 정도로 많다. 온라인 게임 서버의 네트워크 트래픽은 사용자가 증가할 때마다 산술증가가 아니라 기하급수로 증가한다. 좋은 게임 서버의 개발도 중요하지만 서비스가 시작되면 회선에도 많은 투자를 해야한다.
리스트 1 : 시스템을 정지시키는 간단한 프로그램
#include "process.h"
#include "stdio.h"
unsigned __stdcall thread(void* arg)
{
while (1) {
}
return 0;
}
int main()
{
int i;
for (i = 0; i < 3000; i++) {
_beginthreadex(NULL, 0, thread, 0, 0, NULL);
}
getch();
return 0;
}
멀티스레드 프로그래밍
서버 프로그래밍에서 가장 중요한 요소 중의 하나가 스레드(thread)다(스레드의 정의와 스레드 관련 API 함수들에 대해서는 지면관계상 자세히 다루기 힘들기 때문에 생략하겠다. 스레드는 프로세스 내의 작은 프로세스들이라고 이해하고 넘어가도 내용을 이해하는 데는 별다른 문제는 없을 것이다).
멀티태스킹이 지원되는 OS에서는 동시에 여러 개의 프로세스가 실행되는 것이 가능하다. 윈도우 95나 NT같이 완전한 선점형 멀티태스킹 OS라면 백그라운드로 프린트나 파일 복사 같은 작업을 하고 있더라도 포그라운드로 실행중인 프로그램에 별로 영향을 미치지 않고 여러 개의 작업을 동시에 수행할 수 있다. 멀티태스킹 뿐만 아니라 멀티스레드가 지원되는 OS라면 여러 개의 프로그램을 동시 실행시키는 것뿐만 아니라 한 프로그램 또는 프로세스 안에 여러 개의 자식 프로세스(스레드)들을 만들 수 있다. 한 프로그램 내에서도 현재 작업을 중단하지 않고 여러 개의 일을 수행하는 것도 가능하다. 예를 들어 파일을 읽으면서 읽은 양을 다이얼로그 박스에 표시한다던지, 워드프로세스에서 사용자의 입력과 동시에 맞춤법을 맞추는 등 여러 가지 면에서 편리하게 사용이 가능하다.
편해 보이기는 하지만 이 스레드 또한 양날의 칼이다. 잘 사용하면 문제가 없지만 잘못 사용하면 작업을 빨리 끝내는 것이 아니라 오히려 시스템의 속도를 떨어뜨릴 수도 있다.
아무리 멀티태스킹, 멀티스레드를 지원하는 OS라고 해도 결국은 한정된 자원인 CPU를 나눠서 사용하는 것일 뿐이다. 어떤 컴퓨터에 5개의 프로그램과 이 프로그램들에서 만든 100여 개의 스레드가 실행중이라고 할 때 그냥 보기에는 모두 동시에 실행이 되고 있는 것처럼 보이지만 실제로는 그 컴퓨터에 CPU가 하나가 설치되어 있던 2개 또는 8개 이상의 CPU가 달려있던지 결국은 제한된 CPU의 파워를 타임슬라이스(time slice)로 쪼개서 사용하고 있는 것뿐이다. 아무리 잘 만들어진 멀티태스킹 OS라도 CPU라는 한정된 자원을 나눠 사용하는 프로세스와 스레드들이 서로 긴밀하게 협조하면서 실행되게 만들어지지 않는다면 제대로 작동하지 않게 된다.
리스트 1은 간단한 예제지만 OS의 작동을 거의 멈추게 할 수 있다. beginthreadex() 함수는 이름에서 알 수 있듯이 새로운 스레드를 시작하게 하는 함수다. _beginthread의 세 번째 파라미터는 새로운 스레드로 실행될 루틴의 시작 주소이고 네 번째 파라미터는 이 루틴의 변수값이다. 리스트 1은 아무 것도 하지 않고 무한루프를 도는 스레드 3,000개를 만드는 프로그램이다. 비주얼 C++가 깔려 있다면 컴파일하고 실행하자(이 기사의 모든 예제는 비주얼 C++ 6.0을 기준으로 만들어졌다).
C:\>cl /MDd test.c
(/MDd은 멀티스레드 라이브러리를 사용한다는 옵션)
C:\>test
이 프로그램을 실행시키면 실행환경의 OS가 윈도우 NT 4.0이건 윈도우 2000이건 바로 다운된다. 물론 OS가 완전히 다운되는 것은 아니고 CPU의 대부분을 3,000개의 아무 일도 하지 않는 무한루프가 차지하기 때문에 태스크 스위칭이나 사용자의 입력을 전혀 받지 못하는 상태가 된다. 즉, 사용자의 입장에서는 어떤 입력에도 반응하지 않고 test.exe를 죽이기 위해 태스크 매니저를 띄우려고 해도 아무런 반응이 없는, 사실상 시스템이 죽은 상태가 된다. 아무리 멀티태스킹 OS라고 해도 프로세스가 아무 일도 하지 않는 무한루프 while (1) { }을 실행시키면 전체 시스템의 속도가 많이 떨어질텐데 이런 루틴 3,000개가 동시에 돌아간다고 생각하면 당연한 결과이다.
다음은 약간 다른 버전의 thread() 함수다.
unsigned __stdcall thread(void* arg)
{
while (1) {
_sleep(50);
}
return 0;
}
_sleep() 함수는 현재 실행중인 프로세스를 잠시 대기상태가 되게 하는 함수다. 파라미터는 대기상태로 있는 시간이다(단위는 밀리초). 파라미터로 1,000을 주면 1초동안, 60,000을 주면 1분동안 대기상태가 된다(대기상태에 있는 스레드나 프로세스는 CPU를 거의 사용하지 않는다). 그래서 위의 루틴은 0.05초마다 한번씩 루프를 돌게 된다. 다시 컴파일해서 실행시켜보면 사용하는 시스템마다 약간씩 다르겠지만 느려지는 느낌이 들기는 해도 별다른 무리없이 PC를 사용할 수 있다.
멀티 플레이어 온라인 게임의 서버뿐만이 아니라 다른 범용적인 목적의 멀티유저용 프로그램의 서버라도 위와 같은 과다한 스레드의 사용문제에 부딪히게 된다. 동시에 여러 명의 사용자가 접속했을 때 이들의 요구에 동시에 응답하기 위해서는 스레드의 사용이 필수겠지만 수십 개의 스레드를 만들고 무한정 사용자의 입력을 기다릴 수는 없다. 동시 유저가 1,000명이 될 것이라고 가정하고 1,000개의 스레드를 만든다면 이론적으로는 맞지만 놀고 있는 스레드들이 CPU를 대부분 사용하므로 서비스의 전체 속도는 떨어질 것이 확실하다. 이러한 문제를 막기 위해 사용자가 접속할 때마다 스레드를 만든다고 해도, 만약 이 스레드가 필요하지 않은 경우에도 실행이 되고 있다면 같은 문제에 봉착하게 된다.
따라서 충분한 수의 스레드를 만들어 스레드 풀에 넣은 후에 이 스레드들을 사용하기 전까지는 대기상태에 있게 하는 방법이 필요하다. _sleep()은 특정 시간동안 대기상태에 있게 하지만 프로그래머가 정한 특정한 때에만 스레드나 프로세스가 실행되게 하고 싶다면 Win32의 이벤트 오브젝트(event object)를 사용하면 된다. 이벤트 오브젝트를 사용하면 필요하지 않을 때는 대기상태에 두었다가 필요할 때 이벤트를 발생시켜 프로세스를 깨울 수 있다(리스트 2).
CreateEvent()는 이벤트 오브젝트를 만드는 Win32 함수이며, SetEvent()는 이벤트를 발생시키는 Win32 API 함수다. WaitForSingleObject() 함수는 하나의 특정 이벤트를 기다리는 함수로 첫 번째 파라미터는 기다릴 이벤트 오브젝트의 핸들, 두 번째 파라미터는 기다릴 시간이다(단위는 밀리초). 두 번째 파라미터를 1,000으로 주면 WaitSingleObject() 함수는 1초동안 이벤트가 일어나기를 기다린다. INFINITE는 winbase.h에 미리 선언되어 있는 상수로 이벤트를 무한히 기다리게 된다. WaitForSingleObject()는 정해진 시간에 기다리는 이벤트가 발생하지 않으면 WAIT_TIMEOUT을 리턴한다.
CreateEvent() 함수의 두 번째 파라미터는 이벤트가 발생한 후에 이벤트의 신호(signal)를 리셋할 것인지 아니면 자동으로 리셋될 것인지를 TRUE(1)/FAL SE(0) 값으로 결정한다.
이벤트 신호(signal)는 교통신호등의 신호와 같은 거의 같은 의미다. 횡단보도에서 파란불을 기다리는 자동차처럼 WaitForSingle Object()에 있는 프로세스나 스레드는 신호(signal)가 들어오기를 기다리고 있다. 이 값을 TRUE(1)로 주면 한번 신호가 들어간 후에도 계속 신호등은 파란불인 상태로 남아있게 된다. 그래서 뒤에 대기 중이던 차들도 계속 통과하는 것이다. 이 신호를 리셋하기 위해서는 프로그래머가 ResetEvent() 함수를 이용해서 이벤트의 신호(signal)를 리셋해야 한다. FALSE(0)로 주면 자동으로 리셋이 된다. 즉, 한대의 자동차가 통과하고 나면 신호등은 다시 즉시 빨간불이 되어 한번에 한대의 자동차만 지나가게 된다. 이벤트 오브젝트의 모든 사용이 끝나면 CloseHandle() 함수로 오브젝트를 다시 커널에 반환한다. 더 자세한 것은 Win32 레퍼런스 가이드나 비주얼 C++ 헬프를 참고하기 바란다.
리스트 2를 컴파일해서 실행하고 ‘h’키를 누르면 ‘Hello world!’를 도스창에 출력하고 ‘c’키를 누르면 프로그램이 종료된다. 프로그램이 실행되면 처음에는 thread() 루틴은 WaitSingleObject() 함수에서 hEvent 이벤트를 무한히 기다리게 된다. 사용자가 ‘h’키를 누르면 SetEvent() 함수로 hEvent 이벤트를 발생하고 thread()는 대기상태에서 빠져나와 printf(“Hello world!”)를 실행하고 다시 WaitSingleObject() 함수에서 무한히 hEvent 함수를 기다리게 된다. ‘c’값을 눌러 루프를 벗어나면 프로그램은 끝난다. 이때 따로 스레드를 닫지 않아도 thread()를 실행중인 스레드는 메인 프로세스의 자식 프로세스이기 때문에 OS에 의해 자동으로 없어진다. 하지만 thread() 스레드가 끝나고 데이터의 초기화나 다른 작업이 필요할 때는 어떻게 할까? 리스트 3을 보자.
리스트 2에서 한 개의 이벤트 오브젝트를 사용한 것에 반해 리스트 3은 3개의 이벤트 오브젝트를 사용하고 있다.
한번에 여러 개의 이벤트 오브젝트를 기다리기 위해 이벤트 오브젝트 Win32 API 함수 중에서 WaitFor MultipleObjects() 함수를 사용하고 있다. WaitFor MultipleObjects()는 WaitForSingleObject()와 달리 하나의 이벤트 오브젝트가 아니라 한 개 이상의 여러 개의 이벤트를 기다릴 수 있다.
WaitForMultipleObjects() 함수의 첫 번째 파라미터는 기다릴 이벤트의 개수, 두 번째 파라미터는 기다릴 오브젝트들, 세 번째 파라미터는 여러 개의 오브젝트 중 하나를 기다릴 것인지 아니면 여러 개의 이벤트 오브젝트를 모두 기다릴 것인지를 정한다. 이 값을 TRUE(1) 값으로 설정하면 기다리고 있는 여러 이벤트가 모두 발생해야 대기상태를 빠져나가고, FALSE(0) 값을 주면 기다리고 있는 이벤트들 중에서 하나의 이벤트만 발생해도 대기상태를 벗어나게 된다.
WaitForMultipleObjects() 함수의 리턴값은 발생한 이벤트의 인덱스값이나 에러가 발생할 경우의 에러코드다. 리스트 3에서는 만약 hHelloEvent 이벤트가 발생하면 0을, hByeEvent 이벤트가 발생하면 1을 리턴한다.
리스트 2 : 이벤트 오브젝트
리스트 3을 컴파일하고 실행시킨 후 ‘h’키를 누르면 SetEvent(hHelloEvent)가 hHelloEvent를 발생해서 도스창에 ‘Hello world!’를 출력하는 것은 리스트 2와 같지만 ‘c’키를 누르면 hByeEvent 이벤트가 발생된다. WaitForMultipleObjects()는 hHelloEvent 이벤트 뿐만 아니라 hByeEvent 이벤트 역시 기다리고 있으므로 루프를 벗어나 ‘Bye’출력을 하고 hCloseEvent 이벤트를 발생시킨다. 이때 main()에서는 ‘c’키를 눌렀기 때문에 루프를 벗어나서 다음 라인에 있는 WaitFor SingleObject(hCloseEvent, INFINITE); 에서 hClos eEvent 이벤트를 기다리고 있기 때문에 대기상태에서 벗어나게 된다. 프로그램은 ‘Cloed’를 출력하고 종료된다.
멀티스레드 프로그래밍에서는 이와 같이 이벤트 오브젝트를 이용하거나 전역변수를 사용하면 스레드 간 통신 문제를 해결할 수 있다. 하지만 이외에도 여러 개의 스레드가 같은 데이터를 사용할 때 문제가 발생할 수 있다.
예를 들어 A, B, C 3개의 스레드가
int data = 0;
의 값을 모두 공통으로 사용한다고 할 때, 동시에 2개의 스레드가 data에 1을 더하는 오퍼레이션을 실행한다면 data의 값이 1이 될 것인지 아니면 2가 될 것인지는 아무도 모른다. 이렇게 스레드들이 사용하는 데이터가 숫자값이라면 그냥 틀리는 문제로 넘어가겠지만 만약 링크드 리스트나 트리같은 데이터 구조일 때는 운이 좋으면 데이터의 구조가 깨질 것이고, 운이 나쁘다면 프로그램 자체가 access violation 에러를 발생시키고 다운될 것이다.
이러한 문제를 피하기 위해 Win32 API에는 동기화 함수들(Synchronization Functions)이 준비되어 있다. 이 글에서는 모든 함수들과 오브젝트들을 다룰 수는 없기 때문에 CRITICAL_SECTION과 Interlocked 함수들만 다루도록 하겠다(Win32 동기화 함수들에 대해 더 알고 싶은 사람들은 Win32 API 레퍼런스 매뉴얼을 찾아보거나 MSDN 유저는 동기화(Synchronization)항목을 찾아보기 바란다). 크리티컬 섹션(Critical section)은 중대, 치명적이라는 Critical의 의미대로 프로그램 내에 한번에 한 개의 스레드만 진입이 필요한 영역을 의미한다. 크리티컬 섹션으로 정의된 영역은 어떤 스레드가 크리티컬 섹션에 들어가려고 해도 이미 다른 스레드가 이 영역에 들어가 있는 상태라면 뒤에 진입하려는 시도를 했던 스레드는 대기상태로 들어간다. 그리고 먼저 이 영역에 들어갔던 스레드가 이 영역을 벗어나면 대기상태에 있던 스레드는 크리티컬 섹션으로 들어가게 된다. Win32에서 크리티컬 섹션은 코드에서 크리티컬 섹션이라고 정의하는 것이 아니라(C나 C++에는 불행히 이런 문법이 없다) CRITICAL_SECTION이라는 스트럭처를 이용해서 가상으로 정의해서 사용한다. 즉, 같은 CRITICAL_SECTION 스트럭처를 사용하는 스레드는 같은 크리티컬 섹션으로 진입하는 스레드로 간주된다. 크리티컬 섹션으로 들어가는 API는 Enter Critical Section(), 벗어났다고 알리는 API는 Leave CriticalSec tion()이다. 자세한 내용은 다음 예제를 통해 살펴보자. Interlocked 함수는 이름이 Interlocked로 시작되는 함수들로 특정 32비트 변수에 대해 한 개 이상의 스레드가 동시에 접근하는 것을 막는 함수들이다. Interlocked 함수들은 다음과 같은 것들이 있다.
InterlockedCompareExchange
InterlockedCompareExchangePointer
InterlockedDecrement
InterlockedExchange
InterlockedExchangeAdd
InterlockedExchangePointer
InterlockedIncrement
이 중 예제에서 사용할 InterlokcedIncrement를 보자. 함수의 스펙은 아래와 같다. 이 함수는 32비트 변수값을 1 증가시키는 기능을 한다.
LONG InterlockedIncrement(LPLONG lpAddend);
파라미터는 32비트 변수의 주소이고 리턴값은 증가된값이다. 즉
int nNumber = 1;
int nResult;
nResult = InterlockedIncrement((long*) &nNumber);
의 결과는 nNumber값은 2가 되고 nResult에도 nNumber의 증가값인 2가 저장된다. 아래 예제는 Critical section과 Interlocked 함수를 사용한 한 개의 데이터값을 여러 개의 스레드가 동시에 사용하는 프로그램이다.
리스트 4는 10개의 스레드가 하나의 변수 int data을 랜덤한 시간 간격(0~1000밀리초)으로 1씩 증가시키고 이를 화면에 출력하는 프로그램이다. 이때 크리티컬 섹션을 사용하지 않는다면 int data의 값이 어떻게 될까? data++ 오퍼레이션은 실행시간이 짧기 때문에 data=1, data=2, data=3... 순으로 화면에 그려질 것이다. 낮은 확률이지만 동시에 2개 이상의 스레드가 int data값을 바꿔 data=1022, data=1022, data=1023과 같은 결과가 나올지도 모른다.
Win32 Critical section API를 사용하는 방법은 InitializeCriticalSection()으로 CRITICAL_SECT ION 스트럭처를 초기화하고 크리티컬 섹션에 들어갈 때는 EnterCriticalSection() 함수를 사용하고, 나올 때는 LeaveCriticalSection() 함수를 사용하면 된다. 사용이 끝났다면 DeleteCriticalSection()으로 크리티컬 섹션 오브젝트를 제거한다.
리스트 4를 컴파일하고 실행시키면 data=1 data=2 data=3... 이 화면에 계속 출력되고 아무키나 누르면 실행이 종료될 것이다. main()에서는 0.5초 간격으로 종료가 끝난 스레드의 숫자를 체크하며 루프를 돌다 모든 스레드 종료가 확인되면 프로그램을 끝내게 된다. 종료된 스레드의 숫자는 InterlockedIncrement()를 사용해서 증가시킨다. 동시에 여러 개의 스레드가 int closethread의 값을 증가시키려 해도 한번에 하나의 스레드만 int closedthread의 값을 증가시키기 때문에 데이터의 무결성은 보장된다.
리스트 4에서 사용한 크리티컬 섹션이나 다루지 않은 세마포어(semaphore), 뮤텍스(mutex) 등의 동기화(Synchronization) 방법을 사용하면 멀티스레드 프로그램에서 다수의 스레드가 하나의 공용 데이터를 사용한 것에 대한 무결성을 보장할 수 있다. 하지만 크리티컬 섹션, 뮤텍스, 세마포어 등을 이용해서 특정 데이터 사용 전에 락(lock)을 걸고 데이터의 사용이 끝난 후에 락(lock)을 푸는 것으로 데이터의 무결성을 보장할 수 있을지 모르지만, 여러 개의 락을 사용할 때 잘못된 순서/방법으로 사용할 경우 쉽게 데드락(dead lock)을 초래할 수도 있다. 리스트 5를 보자.
리스트 5의 두 코드는 가상의 머그 서버에서 돌아가는 코드로 게임 내의 데이터베이스에 액세스하는 코드들이다. 이 가상의 서버는 동시에 수백 명의 사용자를 감당하기 위해 수십 개의 스레드를 사용하고 있고, 게임 내의 캐릭터가 죽거나 이동/로그인/로그아웃하고 아이템의 사용/이동이 빈번하기 때문에 2개의 CRITICAL_SECTION cs1과 cs2를 사용해서 유저 데이터를 관리한다. cs1은 유저의 데이터를, cs2는 아이템의 데이터를 액세스할 때 사용하는 크리티컬 섹션 오브젝트다.
언뜻 보기에는 맞는 것 같다. 하지만 만약 X라는 스레드가 리스트 5의 A 부분에서 cs2를 사용해서 cs2의 크리티컬 섹션으로 들어가려고 시도중이고, Y라는 스레드는 B 부분에서 cs1의 크리티컬 섹션으로 진입을 시도하고 있다면 X 스레드가 cs2를 벗어나야 Y 스레드가 cs1에 진입할 수 있고, X 스레드는 Y 스레드가 cs1을 벗어나야 cs2로 들어갈 수 있다. X 스레드와 Y 스레드가 서로 돌려줄 수 없는 것을 기다리고 있으므로 영원히 기다려야 한다. 명백한 데드락(dead lock)이다.
위의 데드락은 쉬운 편이라 누구나 쉽게 찾을 수 있는 것이지만 수천 명의 유저가 동시에 플레이 가능한 머그 게임의 서버일 경우, 전체 서버에 사용되는 락(lock) 오브젝트의 숫자가 동시 접속중인 사용자의 2~3배가 되는 경우가 빈번히 일어날 수 있다. 이러한 경우에 데드락을 막는 것은 매우 어렵다. 한 개의 스레드가 데드락이 될 경우 얼마 후에 데드락이 걸린 스레드에 사용된 락에 접근하는 모든 스레드가 같이 데드락에 빠지게 된다. 이런 데드락 문제는 실행환경의 복잡도가 올라갈수록 발생할 확률이 높아지기 때문에 동시 접속자의 숫자가 많을 때 발생하기 쉽고 같은 서버 프로그램이라도 사용자의 숫자가 적다면 발생확률이 낮다. 이런 버그는 개발기간에는 발생 자체가 힘들다. 서비스와 동일한 조건을 맞추기 위해서는 테스트 요원을 수천 명씩 뽑아야 하기 때문에 찾는 것뿐만 아니라 디버깅도 매우 힘들다. 따라서 프로그래머는 이러한 락(lock) 오브젝트들의 사용에 자신만의 규칙을 세우고 코딩 때는 반드시 이 원칙을 지켜서 개발을 해야할 필요가 있다.
리스트 5의 데드락 문제는 두 개의 크리티컬 섹션을 사용할 때 반드시 cs1를 통과한 다음 cs2의 크리티컬 섹션으로 진입하는 것으로 진입 순서를 정하면 해결이 가능하다. 즉, 아래와 같이 사용하면 데드락은 피할 수 있다.
EnterCriticalSection(&cs1);
...
EnterCriticalSection(&cs2);
...
LeaveCriticalSection(&cs2);
...
LeaveCriticalSection(&cs1);
리스트 4 : Critical section과 interlocked 함수
클라이언트 & 서버 프로그래밍
그래픽 머드는 텍스트 머드에서 발전한 것이고 텍스트 머드는 채팅에서 나왔다. 이런 진화과정을 보면 그래픽 머드의 기본원리가 사실은 채팅과 그렇게 다르지 않다고 생각할 수도 있다. 최근에 실제 상용 서비스 중인 여러 채팅 서비스들이 채팅의 원래 기능인 텍스트의 전송 이외에 여러 가지 부가 서비스를 지원하고 있지만, 채팅 서비스의 기본 서비스는 ‘같은 채팅방에 있는 사람들에게 한사람이 전송하는 문장을 전파한다(broadcast)’일 것이다. 간단한 형태의 채팅서버를 만들고 싶다면 아래의 조건을 만족하는 서버 프로그램을 만들면 된다.
① 소켓을 열고 새로운 사용자가 접속하길 기다린다.
② 사용자가 접속하면 접속자 리스트에 추가한다.
③ 접속자가 문장을 서버로 보내면 모든 접속자에게 문장을 전송한다.
④ 접속이 끊기면 접속자 리스트에서 삭제한다.
클라이언트 쪽은
① 소켓을 열고 서버에 접속한다.
② 사용자가 문자를 입력하고 엔터키를 치면 서버에 문자열을 전송한다.
③ 서버에서 문자열을 보내면 화면에 출력한다.
클라이언트 쪽은 소켓프로그래밍에 대한 약간의 지식이 있다면 그리 어렵지 않게 구현할 수 있을 것이다. 서버쪽 기능들은 앞에서 다룬 멀티스레드를 이용, 2개의 스레드 루틴을 만드는 것으로 간단히 구현이 가능하다. 하나는 사용자의 접속을 처리하는 스레드이고 두 번째는 접속한 사용자를 처리하는 스레드이다. 사용자의 접속을 처리하는 스레드를 ServerThread라 하고 접속한 클라이언트의 패킷처리와 소켓관리를 처리하는 스레드를 UserThread라 부르기로 하자. 이 두 개의 스레드를 간단한 슈도(suedo) 코드로 정의하면 리스트 6과 같다.
ServerThread()는 처음에 서버 프로그램이 시작할 때 하나가 만들어진다. ServerThread()는 처음에 소켓을 초기화하고 초기화가 끝나면 새 사용자가 접속하기를 무한히 기다린다. 접속을 기다리다 새로운 사용자가 접속할 때마다 ServerThread()는 새로운 User 오브젝트를 만들고 새롭게 열린 소켓을 처리할 UserThread()를 만든다.
UserThread()는 wait_event(user.socket) 소켓에서 발생하는 사건(소켓이 닫혔다거나 아니면 소켓에 읽기 준비가 되었다 등의 이벤트)을 기다린다. 이때 소켓이 끊기거나 읽을 데이터가 소켓에 들어오면 발생한 이벤트를 처리한다. 소켓이 닫히는 이벤트가 발생하면 루프를 벗어나 UserThread()를 끝내고, 읽기 이벤트라면 소켓을 읽고난 후 읽은 문자 데이터를 현재 접속해 있는 접속자들(userlist가 보관하고 있는)에게 보낸다.
알고리즘을 설명하는 슈도코드에서는 이런 편리한 문법이 가능하지만 실제 코딩 때는 이러한 문법이 없으니 이렇게 쉽게 구현하는 것이 어렵다고 생각할 것이다. 하지만 WSA(Windows Socket API)를 사용하면 소켓 핸들에 특정 이벤트를 설정하는 것이 가능하다. 이것은 다음 예제에서 설명하도록 하겠다.
userlist 오브젝트는 사용자의 리스트를 관리하는 오브젝트로 여러 개의 스레드가 사용되기 때문에 내부적으로는 CRITICAL_SECTION이나 뮤텍스(mutex) 또는 세마포어(semaphore)같은 락(lock)을 사용해서 여러 개의 스레드가 동시에 userlist에 접근하더라도 데이터의 무결성을 보장해야 한다. 위의 예는 채팅서버를 만들기 위한 알고리즘이지만 몇 가지 추가 사항을 제외하고는 그래픽 머드 서버를 만드는 것과 별로 다르지 않다. 채팅 서비스에서는 채팅 서버와 클라이언트는 누가 무슨 말을 했는지에 대한 문자열에 관한 정보만 주고받는다. 채팅 클라이언트는 사용자가 타이핑한 문자열을 채팅 서버에 보내고 채팅 서버는 전달받은 문자열을 접속해 있는 사용자들에게 전해준다.
그래픽 머드의 서버/클라이언트도 별반 다르지 않다. 전달되고 주고받는 데이터가 단지 문자열이 아니라 여러 가지 타입의 패킷이라는 것이 다를 뿐이다. 리스트 7은 UserThread()의 그래픽 머드용 버전이다.
그럼 실제 구현된 간략화된 형태의 머그 클라이언트와 서버를 보자(그림 1). 클라이언트는 게임화면과 채팅내용, 메시지가 나타나는 로그(log)창, 그리고 채팅 내용을 입력하는 입력창의 구성으로 되어있다. client.exe를 실행한 후 file 메뉴에서 login을 선택하면 그림 2의 대화상자가 열린다. Address에 서버의 주소를 입력하고 Name에 원하는 게임 내의 캐릭터 이름을 입력하고 확인 버튼을 누르면 본 게임에 접속하게 된다. 테스트 서버/클라이언트가 지원하는 기능은 채팅과 캐릭터의 이동뿐으로 공격같은 것은 되지 않는다. 캐릭터와 배경도 그래픽 이미지가 아니라 아스키 코드로 이루어져 있다. 방향키를 누르면 누른 방향으로 캐릭터(U자)가 이동할 것이다. 하지만 만약 이동할 위치에 다른 유저가 있거나 벽이 있다면 캐릭터는 움직이지 않는다.
서버와 클라이언트 중 클라이언트 쪽은 오직 서버와 통신만 하는 일반적인 윈속(Winsock) 프로그램이기 때문에 별다른 테크닉이 사용되지 않았다. 따라서 이 글에서는 서버 쪽을 중점적으로 설명하겠다.
리스트 8은 ServerThread()를 실제로 구현한 코드로 클라이언트/서버 중 서버의 코드로 server.cpp에 있는 함수다. 알고리즘은 리스트 6의 슈도코드와 거의 비슷하므로 알고리즘 자체의 이해에는 어려움이 없을 것이다. ServerThread()는 서버의 메인 윈도우가 만들어진 후에 스레드로 실행되는 함수로 우리가 만들 머그 서버의 메인 루틴이다. Winsock 부분은 전형적인 Winsock 서버의 코드들이다. WSAStartup()으로 Winsock을 초기화시키고, 소켓(socket() 테스트 서버가 사용하는 1001번이다)을 열고, 이름을 정하고(bind()) 접속을 기다리고(listen()), 접속이 신청되면 허락한다(accept()).
새로운 접속이 생기면 new User(hSocket)로 새 유저 오브젝트를 만들고 g_world에 등록한다. 그리고 등록한 클라이언트에 접속한 유저의 이름을 묻는 패킷 S_NAME을 보낸다. g_world는 전체 게임세계에 있는 모든 오브젝트를 관리하는 클래스의 인스턴스로 접속한 사람들의 이름/위치/id를 가지고 있고, 전체 게임 내의 맵(map) 데이터를 가지고 있다. 이 맵 데이터를 이용해서 사용자의 캐릭터 이동시 벽이나 장애물 또는 접속해 있는 다른 사용자의 캐릭터들과의 충돌체크를 한다. ServerThread()는 새 접속자의 등록이 끝나면 접속한 사람별로 UserThread() 스레드를 실행한다.
이 테스트용 클라이언트/서버 환경에서 사용되는 패킷은 아래와 같은 구조로 되어 있다. 패킷의 처음 2바이트는 전체 패킷의 길이가 저장되고, 세 번째 바이트에는 패킷의 번호가 저장된다. 네 번째 바이트부터 패킷의 끝까지는 패킷의 몸체(body)가 저장된다.
User::Send(char)는 패킷몸체가 없는 패킷을 보내는 함수다. 패킷몸체가 없고 패킷번호만 보내기 때문에 이 함수로 보내지는 패킷은 항상 3바이트의 크기만 가진다는 것을 알 수 있다. 서버에서 클라이언트로 전달되는 패킷 중 S_MOVE라는 패킷이 있다. 이 패킷은 움직인 유저의 id(4바이트)와 x(4바이트), y(4바이트)로 구성되어 있다.
이 패킷을 인코딩하는 함수는 아래와 같다(SetChar(), SetInteger(), SetShort(), GetChar(), GetInteger(), GetShort()는 서버와 클라이언트가 공통으로 사용하는 util.cpp에 있다).
char szPacket[512];
char* pPacket = szPacket + 2;
pPacket = SetChar(pPacket, S_MOVE);
// 3번째 바이트에 패킷번호
pPacket = SetInteger(pPacket, pUser->Id());
// 4번째 바이트부터 id
pPacket = SetInteger(pPacket, pUser->X());
// 8번째 바이트부터 x
pPacket = SetInteger(pPacket, pUser->Y());
// 12번째 바이트부터 y
SetShort(szPacket, pPacket - szPacket);
// 0번째에 2바이트의 패킷 길이
클라이언트 측에서 S_MOVE 패킷의 디코딩은 아래와 같다.
Int nId;
int nX;
int nY;
pPacket = GetInteger(pPacket, nId);
pPacket = GetInteger(pPacket, nX);
pPacket = GetInteger(pPacket, nY);
WSAEVENT hEvents[] = { hEvent1, hEvent2, hEvent3 };
...
WSAWaitForMultipleEvents(3, hEvents, FALSE, WSA_INFINITE, FALSE);
...
리스트 7 : 그래픽머드용 UserThread() 슈도코드
UserThread(user)
{
while (true) {
event = wait_event(user.socket)
// 소켓의 이벤트를 기다린다
if (event == event_close) { // 소켓이 닫히면...
userlist.delete(user) // 사용자 삭제
break // 루프를 벗어난다
}
else if (event == event_read) {
// 읽기 이벤트 발생
packet = read_socket() // 소켓을 읽는다
user.packet(packet)
}
}
}
user::packet(packet)
{
switch (packet) {
case move :
move(packet); // user를 이동한다
userlist.seemove(user);
// 접속자들에게 움직임을 알린다
break;
case say :
userlist.seesay(packet); // 채팅을 처리한다
break;
}
}
리스트 8 : server.cpp의 일부
WSA로 시작하는 함수들은 Win32에서 지원하는 윈속 함수들이다. WSAEventSelect() 함수는 소켓핸들에 네트워크 이벤트가 정의된 이벤트 오브젝트를 설정한다.
설정한 소켓에 지정한 네트워크 이벤트가 발생하면 이벤트 오브젝트에 신호(signal)가 세팅된다. 따라서 만약 이 이벤트 오브젝트를 기다리고 있는 프로세스가 있다면 그 프로세스는 대기상태에서 벗어나게 된다.
WSAEVENT hRecvEvent = WSACreateEvent();
...
WSAEventSelect(pUser->Socket(), hRecvEvent, FD_READ | FD_CLOSE);
pUser->Socket()은 소켓핸들을 리턴하는 User 클래스의 멤버 함수다. 위의 코드는 hRecvEvent 이벤트 오브젝트에 FD_READ와 FD_CLOSE 네트워크 이벤트를 설정하고 pUser->Socket() 소켓에 hRecvEvent 오브젝트를 연결한다. 이렇게 하면 pUser->Socket()에 읽기 준비가 되었거나 소켓이 닫히면 hRecEvent 이벤트가 발생한다. 이때 주의할 것은 하나의 소켓에는 하나의 이벤트 오브젝트만 연결이 가능하다. 즉, 아래와 같은 코드는 잘못된 코드다.
WSAEventSelect(hSocket, hEvent1, FD_READ);
WSAEventSelect(hSocket, hEvent2, FD_CLOSE);
두 번째 줄이 실행될 때 첫줄에서 정의한 FD_READ 이벤트는 취소되고 hEvent2에 정의된 FD_CLOSE 네트워크 이벤트만 정상적으로 작동한다. 소켓에 정의된 이벤트를 모두 취소하고 싶다면 아래와 같이 하면 된다.
WSAEventSelect(hSocket, hEvent, 0);
네트워크 이벤트를 기다리는 함수는 앞에서 다루었던 WaitForMultipleObject()와 비슷한 기능을 하며 한 개 이상의 복수 이벤트를 기다릴 수 있다. 네트워크 이벤트를 기다리는 함수에는 WaitForSingleObject()와 같이 한 개의 이벤트만 기다리는 함수는 없다.
WSAWaitForMultipleEvents(1, &hRecvEvent, FALSE, WSA_INFINITE, FALSE);
WSAWaitForMultipleEvents()에서 사용되는 파라미터 역시 WaitForMultipleObject()와 비슷하다.
첫 번째 파라미터는 기다릴 이벤트 오브젝트의 갯수, 두 번째 파라미터는 기다릴 이벤트 오브젝트들의 시작주소, 세 번째 파라미터는 모든 오브젝트를 기다릴 것인지 아니면 오브젝트들 중의 하나만 기다릴지를 결정한다. 네 번째 파라미터는 기다릴 시간이다. WSA_INFINITE값을 주면 영원히 기다리게 된다. 리턴값은 DWORD값으로 발생한 이벤트의 순서를 의미한다. 리스트 10에서는 한 개의 오브젝트를 기다리고 있으므로 항상 0을 리턴할 것이다. 앞에서와 같이 3개의 이벤트를 기다리고 있을 경우 두 번째 이벤트인 hEvent2가 발생하면 리턴값은 1이 될 것이다.
WSAEnumNetworkEvents(pUser->Socket(), hRecvEvent, &event);
한 개의 이벤트 오브젝트에 여러 개의 네트워크 이벤트를 지정하기 때문에 실제 발생한 네트워크 이벤트를 알아내기 위해서는 WSAEnumNetworkEvents()을 이용해서 발생한 이벤트의 상세 정보를 알아내면 된다. 위의 코드는 event structure에 발생한 이벤트의 상세정보를 채운다. event.lNetworkEvents에 실제 발생한 이벤트의 값이 저장된다. FD_CLOSE 이벤트 처리 때 중요한 것은 소켓이 닫혀 FD_CLOSE 이벤트가 발생하더라도 아직 소켓의 버퍼에 읽지 않은 패킷이 남아 있을 수 있다. 그러므로 FD_CLOSE 이벤트가 발생해서 소켓이 끊어진 것이 확인되더라도 recv()에서 -1이 리턴될 때까지 recv()를 콜할 필요가 있다.
리스트 11은 world.cpp와 world.h의 일부이다. World 클래스는 접속한 사용자들의 데이터와 전체 월드의 맵 데이터를 관리한다. 맵 데이터는 캐릭터의 이동시 다른 캐릭터와 벽들 간의 충돌체크에 사용된다. m_mapUser는 C++의 standard library를 사용해서 만든 오브젝트로 접속한 유저의 ID값을 키값으로 User 데이터를 이진트리에 넣어 관리한다(standard library에 관한 자세한 내용은 C++ 레퍼런스 가이드를 참고하기 바란다). m_mapUser 오브젝트와 맵 데이터인 g_pszMap은 동시에 여러 개의 스레드를 사용하기 때문에 크리티컬 섹션으로 관리하고 있다. 만약 m_mapUser 오브젝트를 크리티컬 섹션을 이용해서 한번에 한 스레드가 접근하게 보호하지 않으면 한 스레드가 데이터를 삽입하고 있는 동시에 또 다른 스레드가 데이터를 삭제하려는 시도를 할 수도 있다. 이렇게 되면 m_mapUser의 이진트리 구조는 깨지게 되고 잘못된 메모리 액세스로 프로그램이 다운된다.
World::AddUser()에서는 새로운 유저가 추가될 때 새롭게 추가되는 유저에 ID값을 부여하게 되는데 ID값은 m_nId 값을 InterlockedIncrement()을 이용해서 하나씩 증가시키면서 얻는다. World::Remove() 멤버 함수는 UserThread()에서 소켓이 끊어졌을 경우에 불려진다. m_mapUser에서 소켓이 끊어진 User 오브젝트를 삭제하고 현재 접속해 있는 모든 유저들에게 이 사실을 알려 클라이언트들의 화면에서 접속이 끊긴 유저의 캐릭터가 사라지게 한다. World::Enter()는 반대로 새로운 유저가 접속했을 경우 전체 유저들에게 새 유저의 접속을 알린다. 네트워크 게임에서 패킷의 양이 많아지고 패킷의 크기가 커지면 커질수록 필연적으로 네트워크 트래픽 증가가 따르게 된다. 테스트 서버의 경우 사용되고 있는 캐릭터의 정보는 이름밖에 없기 때문에 별 문제가 없지만, 실제 게임에서는 캐릭터의 스프라이트 정보는 물론이고 현재의 상태, HP, MP 등 보내야할 데이터가 많을 뿐만 아니라 한 화면에 수십명의 캐릭터가 있을 수 있다. 그렇기 때문에 캐릭터의 정보를 계속 보내는 것이 아니라 처음 화면에 나타날 때 캐릭터의 정보를 보내고 다음에 그 캐릭터의 상태가 변할 때(움직이거나 화면을 벗어나거나 그래픽 데이터가 변경되거나)는 바뀐 캐릭터의 ID 값과 새로운 상태만을 보내준다. 이 테스트 서버에서도 새로운 유저가 접속할 때 S_ENTER 패킷에서 캐릭터의 이름과 위치를 보낸 후 다음 패킷부터는 캐릭터와 ID 값만 가지고 통신을 하게 된다.
리스트 11 : world 클래스
마치며
이 글에서 사용된 테스트용 서버와 클라이언트는 사실 미완성 버전이다. 전투나 HP 관리, 사용자 데이터의 저장, NPC 처리 등 구현되지 않은 것 투성이다. 처음 이 글을 시작할 때 구현하고 싶었던 것은 네트핵(Nethack)의 멀티유저 버전이었다. 이 글을 읽는 독자들 중 멀티유저 게임의 개발에 관심이 있는 사람이라면 이 미완성 프로그램을 발전시켜 완전한 형태의 네트핵 서버/클라이언트를 만드는 것에 도전해보길 기대하며 글을 마치겠다.
프로세스간 동기화 (Interprocess Synchronization)
멀티쓰레드 환경에서 세마포어, 뮤텍스와 크리티컬 섹션 오브젝트는 어떻게 다른가 살펴보자. 아래 코드는 전형적인 뮤텍스 오브젝트의 사용방법이다.
hMutex = CreateMutex (NULL, FALSE, “MyMutexObject”);
// 뮤텍스 오브젝트를 만든다.
...
unsigned __stdcall thread1()
{
...
WaitForSingleObject(hMutex, INFINITE); // 크리티컬 섹션으로 진입
...
ReleaseMutex(hMutex); // 크리티컬 섹션을 빠져나온다.
...
}
...
CloseMutex(hMutex); // 사용이 끝난 뮤텍스 오브젝트를 없앤다.
뮤텍스 오브젝트는 만들어질 때 이미 신호(signal)가 셋트되어 있는 상태다. 따라서 처음 WaitiForSingleObject(hMutex)를 콜(call)하는 쓰레드는 기다림없이 바로 크리티컬 섹션으로 들어갈 수 있다. 그리고 ReleaseMutex(hMutex)를 콜하기 전까지 신호(signal)는 리셋되어 있는 상태이기 때문에 다른 쓰레드들은 이 크리티컬 섹션으로 진입할수 없다. 뮤텍스 오브젝트와 크리티컬 섹션 오브젝트 모두 크리티컬 섹션의 기능을 수행하고 사용법도 비슷해 보인다.
둘 간의 차이는 뮤텍스 오브젝트는 interprocess synchronization (프로세스간 동기화)가 가능한 오브젝트이고, 크리티컬 섹션 오브젝트는 그렇지 않다는 것이다. CreateMutex()의 3번째 파라미터는 오브젝트의 이름을 스트링으로 지정하는 항목이다(NULL값으로 만들면 다른 프로세스에서 이 오브젝트를 찾을수 없다). 이렇게 만들어진 오브젝트는 지정한 이름으로 OS의 커널에 등록되어 여러 프로세스가 이 오브젝트를 사용하는 것이 가능하다. 만약 프린트를 하려는 프로그램이 2개 이상이 있다면? 여러 프로그램이 각자의 윈도우에 뭔가를 그리려고 동시에 시도한다면? 모두다 흔히 발생하는 일이다. 이때 프로세스간 동기화가 필요하다. OpenMutex(),OpenSemaphore(),OpenEvent()와 같은 API들을 사용하면 오브젝트의 이름으로 다른 프로세스에서 만든 오브젝트의 핸들을 얻을수 있다.
unsigned __stdcall thread2()
{
hMutex = OpenMutex(NULL, FALSE, “MyMutexObject);
WaitForSingleObject(hMutex, INFINITE); // 크리티컬 섹션으로 진입
...
ReleaseMutex(hMutex); // 크리티컬 섹션을 빠져나온다.
}
뮤텍스 오브젝트는 커널에서 만들어지고 크리티컬 섹션 오브젝트는 프로세서에서 만들어지기 때문에 프로세스간 동기화가 필요하지 않을 경우 크리티컬 섹션 오브젝트를 사용하는 것이 속도면에서 약간 빠르다.
| 코드 리뷰 (0) | 2013.08.12 |
|---|---|
| UML - Class Diagram 관계 샘플(좋음) (0) | 2013.07.26 |
| 소프트웨어 아키텍처란 무엇을 의미하는가? (0) | 2013.07.26 |
| [펌] Winsock(소켓)설명_좋음 (0) | 2013.08.09 |
|---|---|
| 소프트웨어 아키텍처란 무엇을 의미하는가? (0) | 2013.07.26 |
| TDD수련법 - by 김창준씨 (0) | 2013.07.24 |
소프트웨어 아키텍처란 무엇을 의미하는가?
‘소프트웨어 시스템을 구성하는 서브시스템과 컴포넌트, 그리고 그것들의 관계를 나타내는 용어이다.’
- Pattern-Oriented Software Architecture, Volume 1: A System of Patterns
‘아키텍처는 컴포넌트로 구체화된 시스템의 기본적인 조직이며 환경
에 대한 관계이고 디자인과 진화를 이끄는 원리이다.’
- IEEE1471
‘소프트웨어 구성요소와 그들이 지니고 있는 특성 중에 외부에 드러
나는 요소의 특성, 그리고 구성요소들 간의 관계를 표현하는 시스템
의 구조나 구조체를 말한다’
- Software Architecture in Practice
몇몇 책에서 나온 소프트웨어 아키텍처에 대한 정의이다. 정의가 조금씩
다르지만 공통적으로 언급하고 있는 것은 소프트웨어 아키텍처란 시스템
을 구성하는 구성요소(서브시스템, 컴포넌트)와 그들(구성요소) 간의 관계
를 나타낸다는 점이다.
| UML - Class Diagram 관계 샘플(좋음) (0) | 2013.07.26 |
|---|---|
| TDD수련법 - by 김창준씨 (0) | 2013.07.24 |
| [펌] SVN 이전 버전으로 복구하기 (2) | 2013.07.10 |
//10.12.20
인터넷에서 김창준씨가 작성한 'TDD 수련법' 보기 (http://xper.org 에 있음)
cf. 책: 테스트 주도 개발 (켄트 벡 저, 김창준 역)
| 소프트웨어 아키텍처란 무엇을 의미하는가? (0) | 2013.07.26 |
|---|---|
| [펌] SVN 이전 버전으로 복구하기 (2) | 2013.07.10 |
| Eclipse의 특정 View 보이기 - 예) Breakpoint, Bookmark list (0) | 2013.05.02 |
출처: http://cafe.naver.com/pfgroup/454
svn 작업하다보면 에러난 상태로 커밋되거나
이전 기록이 보고 싶을때가 있습니다.
이럴땐 History기능을 이용해서 되돌릴수 있습니다.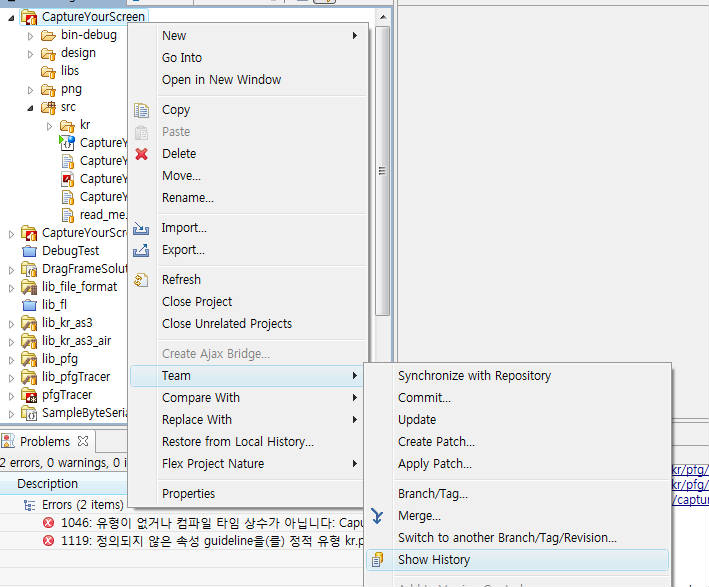
(클릭하면 커집니다)
1. 프로젝트를 우클릭하고 Team > Show History 를 선택합니다.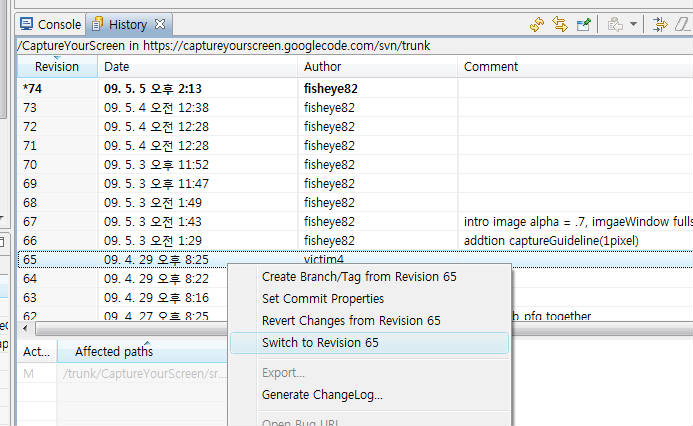
2. 자신이 돌아가고 싶은 버전을 우클릭하고 "Switch to Revision" 을 선택하면 롤백 됩니다.
| TDD수련법 - by 김창준씨 (0) | 2013.07.24 |
|---|---|
| Eclipse의 특정 View 보이기 - 예) Breakpoint, Bookmark list (0) | 2013.05.02 |
| Eclipse 단축키(Shortcut) (0) | 2013.05.01 |
static과 private차이를 물으셨는데.
우선 static과 static이 아닌 것의 차이를 설명드리겠습니다.
1. static이 붙고 안붙은 변수의 차이:
public class Human{
pulbic static long population;/*인구수 static이 붙었습니다.*/
public int age;/*나이 static이 안붙었습니다.*/
}
이런 클래스를 만들었습니다.
인간의 인구수는 변수가 한개만으로 충분하겠지요? 그래서 static을 붙였습니다.
그리고 나이라는 변수는 사람마다 나이가 틀리겠죠? 그래서 static을 안붙였습니다.
사용할 때는 아래와 같습니다.
1.1 static인 변수에 값을 대입하기
Human.population = 7000000000L;
static이므로 new해서 인스턴스를 만들지 않고 direct Access해서 값을 대입하여 사용합니다.
(long형자료형인 경우 숫자뒤에 L을 붙여야 하는거는 아시죠?)
1.2 static이 아닌 변수에 값을 대입하기
Human aMan = new Human();// 1.먼저 생성한 후
aMan.age=26; // 2.대입합니다.
Human aMan2 = new Human();// 1.먼저 생성한 후
aMan2.age=27;// 2.대입합니다.
System.out.println("두명의 나이를 더하면?"+ (aMan.age+aMan2.age));
static이 아니므로 new로 인스턴스를 생성하여 해당인스턴스변수에 값을 대입합니다.
변수에 static이 붙은 변수를 "클래스변수" 혹은 "스태틱변수"라고 하고 static이 안붙은 변수를
"인스턴스변수"라고 합니다. (class와 instance 의 차이는 아시죠? class는 자료형의 템플릿(거푸집)이고 instance는 자료형의 실체 잖아요?)
결론: static이 붙고 안붙는 변수의 차이는 아래 표로 정리를 해보았습니다.
static 키워드가 붙은 변수는 전역(global)으로 값이 사용됩니다.
| static이 붙는 변수 | static이 안붙는 변수 | |
| 전역여부 |
O 전역변수 |
X 전역이 아님, 인스턴스변수 |
| 직접대입가능 |
O Human.population 처럼 다이렉트 Access가 가능합니다. |
X Human aMan = new Human(); aMan.age=10; static이 안붙는 변수를 사용하기 위해 반드시 new를 사용하여 클래스의 인스턴스를 먼저 만들어야지만 사용이 가능합니다.
|
| private,public과의 관계 |
관계는 없지만 주로 public이 사용됨. public static int a; 이런식으로 주로 public이 static앞에 붙습니다. 왜냐하면 static변수는 주로 전역으로 사용되기 때문이죠. - 굳이 private사용하기 사례 private static int m_age; public static int getAge() { return m_age; } public static int setAge(int v) { m_age = v; } m_age변수는 private를 사용하여 감추고 getAge나 setAge는 public을 사용하여 외부에 노출하였습니다. |
- 관계없음.
|
| 머라고 부르나? | 클래스변수 |
인스턴스변수=속성=멤버변수
cf. 그럼 지역변수(로컬변수)는 먼가? {}[단위블럭]안에서 생명주기를 가지는 변수를 지역변수라고 합니다. static Method의 {}안에서 선언된 변수변수는 별개의 thread에 의해 동시에 진입되더라도 독립된 메모리영역에서 생성되어진 값으로 사용됩니다. 즉 static Methoid의 {}안의 선언된 변수와 static 아 아닌 Method의{} 안의 선언된 변수는 똑같이 local variable입니다.
|
| 메모리공간 |
1개 해당자료형의크기만큼자리 잡힙니다. |
n개 - new로 생성된 수만큼 확보 - 선언된시점의 {}[중괄호블럭]안에서 유효하며 {}바깥에서는 메모리에서 적절히 소멸됨.
|
2. static이 붙고 안붙은 method사례:
아래 class참고
public class Human{
pulbic static long population;/*인구수 static이 붙었습니다.*/
public int age;/*나이 static이 안붙었습니다.*/
static
{
population = 7000000000L;//static블럭안에서 static변수의 값을 초기화 할 수도 있습니다.
}
public static void addPopulation(long val)
{
population += val;
//age = 3;//<-- static Method안에서 인스턴스변수의 값을 access 하는 것은 불가능합니다.
//System.out.println(this.hashCode());//<--static Method안에서 this를 access할 수 없습니다.
// this가 클래스의 인스턴스기 때문이죠.
}
public void setAge(int val)
{
age = val;
//System.out.println("인류인구:"+Human.population);//static변수는 전역이므로 어디서는 사용가능합니다.
}
}
위와 같은 클래스를 만들어보았습니다.
2.1 static 키워드가 붙은 함수를 static method[스태틱 메쏘드]라고 합니다.
static메쏘드는 업무로직이 구현된 함수이며,
new를 하지 않고 편리하게 사용이 가능합니다.
- 인스턴스변수를 static함수 내부에 사용할 수 없습니다.
예) int a = Integer.parseInt("3");//<--- parseInt는 static 메소드이므로 new 없이 사용가능합니다.
2.2 static 키워드가 안붙은 함수는 instance함수라고 하는데
get이 붙은 함수는 getter[겟터], set이 앞에 붙은 함수는 setter[셋터]라고 합니다.
위의 예시에서 setAge는 age라고 하는 인스턴스의 속성의 값에
특정한 값을 셋팅하는 setter 입니다.
- new를 한 후 사용할 수 있습니다.
- 인스턴스변수를 매개변수로 전달하지 않고 사용할 수 있습니다.
this.인스턴스변수명 으로 함수내부에서 사용이 가능합니다. this.은 생략 가능합니다.
3. 관련 디자인패턴:
singleton:
만약 인스턴스를 static방법으로 Access하고자하는 경우
싱글톤디자인패턴으로 개발하면 되겠습니다.
싱글톤디자인 패턴은 위에서 설명한 메모리공간에 static은 1개만 들어가는 특징이 있는데
인스턴스도 1개만 만들어서 static변수에 대입하여 사용하는 디자인 패턴입니다.
4. 개발시 유의사항: static변수를 다루는데 있어서 쓰레드 구현시 유의사항이 있습니다.
앞에서 static변수는 전역변수라고 설명드렸습니다.
또한 static변수로 선언된 변수는 전역자원(global resource, global data)에 해당됩니다.
물리적으로 하나의 메모리 공간에 있는 데이터를 처리할 때
유의해할 것은 동시성 제어를 해야 할 때입니다.
즉 동시에 한개의 자원(혹은 데이터)을 가져와서
n개의 쓰레드가 동시에 해당 변수에 접근하였을 때
값을 읽어와서 쓰려고 하는 과정에서 문제가 생길 수 있습니다.
전역자원은 배열의 형태일수도 있는데 for문을 돌리는 있는 중간에 다른 쓰레드에 의해서
배열의 크기가 바뀌거나 할 수 있습니다. 그러면 오류가 생기게 됩니다.
access오류라든지(가령 ConcurrentModificationException)
연산오류(정합성체크를 못하는 연산오류)
그렇기 때문에 전역자원을 멀티쓰레드(쓰레드는 static자원이 아닙니다.)가 다룰때
synchronize를 해줘야 하는 경우가 있습니다. 하나의 thread에 의해서만 해당 자원이 다루어
져야 한다면 synchronize(해당자원){구현...} 이렇게 하면 다음쓰레드는 해당 코드에 동시에
진입하지 않고 먼저실행된 threa의 {}블럭이 끝날때 까지 기다렸다가 다음쓰레드가 실행되겠습니다.
static에 대해 제가 알고 있는 전부라고 해도 과언이 아닙니다.
도움이 되시길 바랍니다.
코드샘플은 제가 이해하시기 좋을 것같은 예로 제가 직접작성하였지만 실제로 돌려보지는 않았습니다.
| [펌] [Eclipse] Juno 버전 이후 Eclipse Marketplace... 메뉴를 추가하는 방법 (0) | 2014.10.03 |
|---|---|
| JUnit TestSuite in Eclipse : 여러 파일 묶어서 테스트하기 (0) | 2013.07.01 |
| Eclipse 사용법 (My) (0) | 2013.06.26 |
Eclipse에서
File - Others - JUnit Test Suite 선택하면, 아래 창 나옴.
여기서 해당 Package를 browse 하고 원하는 class를 선택하면 자동으로 묶어서 파일이 생성됨.
이 파일을 Run As - JUnit Test 돌리면 됨.
(JUnit 버전: v4.8.2)
참고: 수동으로 class 추가하는 방법
http://koronya.tistory.com/63
| java static과 private차이 (0) | 2013.07.05 |
|---|---|
| Eclipse 사용법 (My) (0) | 2013.06.26 |
| for loop to iterate over enum in Java (0) | 2013.06.25 |
* 1개의 파일에서 수정후, 프로젝트내 다른 파일에서 문제를 일으키는지 확인하는 방법
: Problems 창에서 보면 됨 (메뉴위치: Window → Show View → Problems)
: 아래 그림 참고
* 참고:
- error 등이 이상해서 project rebuild 하는 법 : Project -> Clean...
- 자동빌드 활성화하기 : Project -> Build Automatically 가 체크.
| JUnit TestSuite in Eclipse : 여러 파일 묶어서 테스트하기 (0) | 2013.07.01 |
|---|---|
| for loop to iterate over enum in Java (0) | 2013.06.25 |
| [펌] [JAVA] JAVA 요약 (헛갈리는 것 중심으로) 1 (0) | 2013.05.06 |
if ( dir != AAA ) {
...
}
}
cf. 배열을 for 루프에서 처리하기 :
Object[] obj 로 정의
for (Object o : obj) {
// o 를 처리
}| Eclipse 사용법 (My) (0) | 2013.06.26 |
|---|---|
| [펌] [JAVA] JAVA 요약 (헛갈리는 것 중심으로) 1 (0) | 2013.05.06 |
| 나의 eclipse 설정 (key 포함) (0) | 2013.04.08 |
출처: http://notpeelbean.tistory.com/entry/JAVA-자바-프로그래밍시-자꾸-헛갈리는-것들-1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | ArrayList<String> a1 = new ArrayList<String>(); a1.add("abcdef"); ArrayList<String> a2 = new ArrayList<String>();a2 = a1; //Call by Reference//a2 = (ArrayList<String>) a1.clone(); //Call by Value a2.clear();a2.add("ghijk"); System.out.println(a1.get(0));System.out.println(a2.get(0));< |
|
변수의 종류 |
선언위치 |
생성시기 |
|
클래스변수 |
클래스 영역 |
클래스가 메모리에 올라갈 때 |
|
인스턴스변수 |
인스턴스 생성시 |
|
|
지역변수 |
메서드 영역 |
변수 선언문 수행시 |
| for loop to iterate over enum in Java (0) | 2013.06.25 |
|---|---|
| 나의 eclipse 설정 (key 포함) (0) | 2013.04.08 |
| [펌] Eclipse 기본 사용법 (0) | 2013.04.02 |
메인메뉴 Window - Show View - Others 에서
Breakpoint나 Bookmark를 타이핑하면 됨.
| [펌] SVN 이전 버전으로 복구하기 (2) | 2013.07.10 |
|---|---|
| Eclipse 단축키(Shortcut) (0) | 2013.05.01 |
| eclipse plugin (0) | 2013.04.17 |
References in Workspace Shift+Ctrl+G In Windows
Organize Imports Shift+Ctrl+O In Windows
Go to Next Member Shift+Ctrl+Down Editing Java Source
Go to Previous Member Shift+Ctrl+Up Editing Java Source
Move Lines Down Alt+Down Editing Text
Move Lines Up Alt+Up Editing Text
Show Key Assist Shift+Ctrl+L In Dialogs&Windows
| Eclipse의 특정 View 보이기 - 예) Breakpoint, Bookmark list (0) | 2013.05.02 |
|---|---|
| eclipse plugin (0) | 2013.04.17 |
| [펌] Eclipse 3.7 Indigo 한글 폰트 문제 (0) | 2013.04.05 |
StartExplorer Plug-in
: How to open windows explorer on selected resource in Eclipse
http://basti1302.github.io/startexplorer/
Coffee Bytes Floding plugin
http://itekblog.com/code-folding-in-eclipse-tutorial/
Indent Guide (들여 쓰기 가이드 라인)
http://dreamfactory7.tistory.com/201
 pdt_tools.indentGuide_1.2.1.zip
pdt_tools.indentGuide_1.2.1.zip
| Eclipse 단축키(Shortcut) (0) | 2013.05.01 |
|---|---|
| [펌] Eclipse 3.7 Indigo 한글 폰트 문제 (0) | 2013.04.05 |
| How to forcibly close a socket in TIME_WAIT? (linux) (3) | 2012.11.16 |
show line number
Java - Editor - Folding
Keys:
JDK 설치
-> Java library의 코드 (ex. String class의 코드) 를 볼수 있다.
[ JDK를 설칭 방법 ]
1. 이클립스 상단 메뉴의 창(Window) -> 환경설정(Preferences)로
이동
2. 좌측 메뉴중에 Java -> 설치된 JRE(Insalled JREs)를 선택하면 jre7 만 존재하는 것을 확인할
수 있다.
3. 우측에 추가(ADD) -> 표준 VM(Standard VM) ->
다음(Next)
4. JRE를 추가하기 위한 창이 뜨면 디렉터리(Directory) -> 이전에 설치된 JDK 경로를 찾는다
-> 완료(Finish)
5. 설치된 JREs에 방금 추가한 JDK가 추가된 것을 확인할 수 있다. -> JDK를
선택하고 확인(OK)
6. 다시 환경설정의 설치된 JRE를 찾아 들어가면 '실행환경(Execution Environments)'를
확인 할 수 있다.
7. 실행환경을 선택 -> 리스트에서 JavaSE-1.7 선택 -> 호환 가능
JRE(Compatible JREs)의 jdk1.7.0_10[완전일치] 선택 후 확인
* JDK 설치 후 화면
matching brackets 색상을 적색으로 변경
Window >> Preferences >> Java >> Editor. Select Highlight matching brackets. Optionally, you may select Matching brackets highlight from the Appearance color options and click on Color to choose a highlight color. It recommended that you change the color because the default (gray) is difficult to see. Click Apply then OK.
Text file encoding을 MS949에서 UTF-8로 변경 -> 설정안함
(다른 프로젝트에서 *.java 파일 복사시 한글 깨짐 방지 목적 <- 점검중 -> 잘 안됨)
Java font : Consolas 10 으로 설정.
| for loop to iterate over enum in Java (0) | 2013.06.25 |
|---|---|
| [펌] [JAVA] JAVA 요약 (헛갈리는 것 중심으로) 1 (0) | 2013.05.06 |
| [펌] Eclipse 기본 사용법 (0) | 2013.04.02 |
출처: http://www.fliagain.com/blog/entry/Eclipse-37-Indigo-%ED%95%9C%EA%B8%80-%ED%8F%B0%ED%8A%B8-%EB%AC%B8%EC%A0%9C
|
|
|
Eclipse 3.7 버전을 실행하면 한글이 작게 보이는 문제가 있다. 이 문제는 Eclipse Indigo 의 기본 폰트가 Consolar로 설정되어 있기 때문이다.
해결 방법은
1. Windows\Fonts 폴더로 이동
2. 사용하고자 하는 Courier New 폰트를 선택 한 후 마우스 오른쪽 클릭 > 표시 로 설정
3. Eclipse 의 Window -> Perferences -> General -> Appearance -> Colorws and Fonts -> Basic -> Text Font 를 선택한 후 폰트를 변경
끝.
| eclipse plugin (0) | 2013.04.17 |
|---|---|
| How to forcibly close a socket in TIME_WAIT? (linux) (3) | 2012.11.16 |
| svchost.exe의 내부 service 확인방법 (0) | 2012.11.05 |
출처: http://101mong.tistory.com/2
◎에디터간 이동
에디터 간 이동 : Ctrl + F6
뷰 간 전환 : Ctrl + F7
퍼스펙티브 간 이동 : Ctrl +F8
에디터 포커스이동 : F12
◎문자열 외부화
컨택스트 메뉴에서 Source>Externalize Strings
| for loop to iterate over enum in Java (0) | 2013.06.25 |
|---|---|
| [펌] [JAVA] JAVA 요약 (헛갈리는 것 중심으로) 1 (0) | 2013.05.06 |
| 나의 eclipse 설정 (key 포함) (0) | 2013.04.08 |



|
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |





 eclipse-folding-plugin.tar.gz
eclipse-folding-plugin.tar.gz




